📥 检索模块详细信息
要检索给定轨道的模块详细信息,我们需要使用GET track/:id/modules我们在 REST API中提供的
让我们尝试一下该端点,再次为其提供我们的轨道 ID c_0。
我们得到响应,是一个包含我们需要详细信息的模块数组。
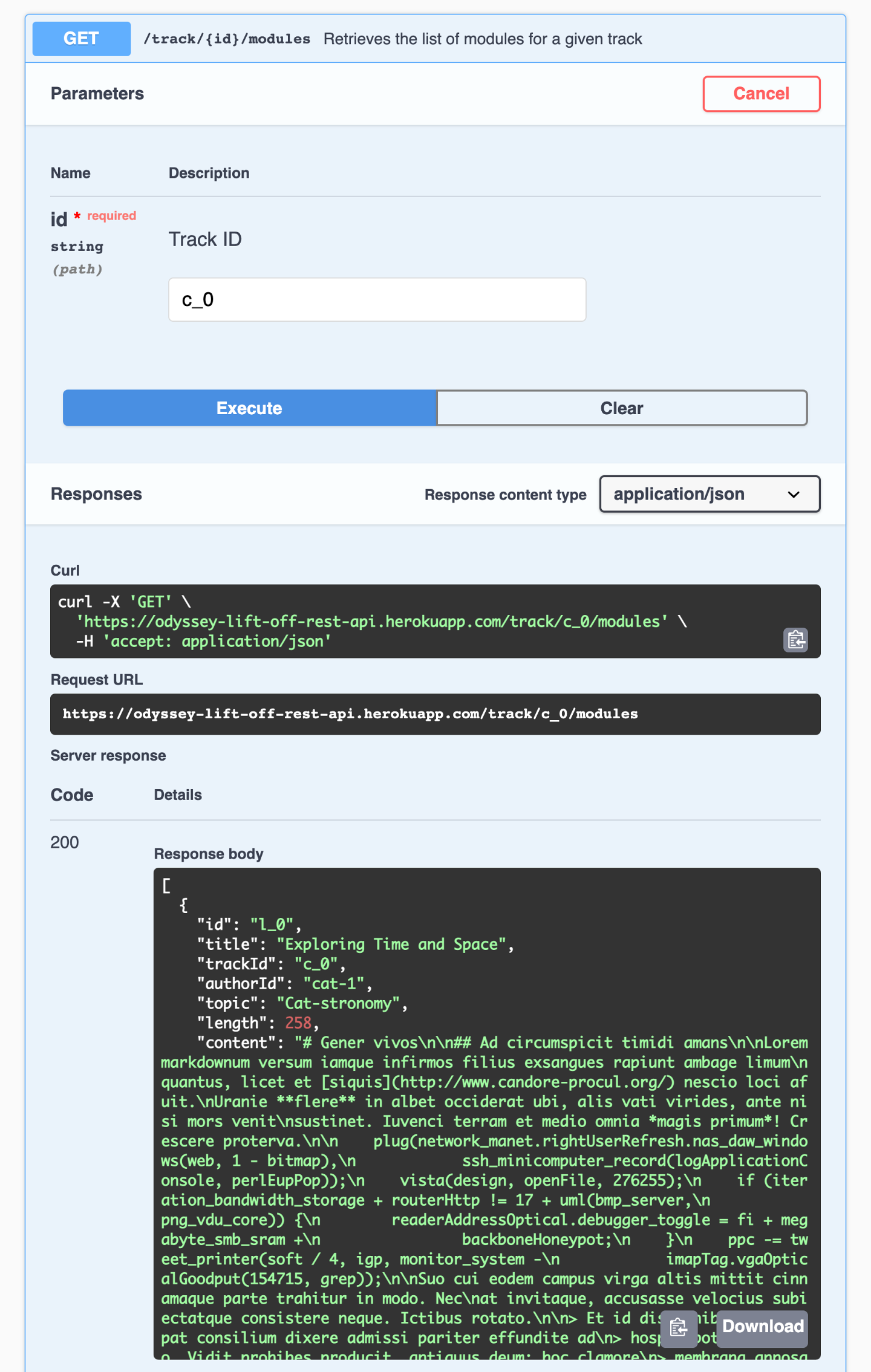
我们的轨道页现在需要 id、title和 length。让我们更新我们的 TrackAPI以调用此端点。
💾 更新 RESTDataSource
在 server/src/datasources文件夹中,打开 track-api.js文件。
让我们创建一个名为 getTrackModules的方法。它将 trackId作为参数。在其中,它将对 track/${trackId}/modules端点进行 get调用,并返回结果。
getTrackModules(trackId) {return this.get(`track/${trackId}/modules`);}
现在我们可以在 解析器中使用这个新数据源方法。让我们跳转回 resolvers.js 文件中的 server/src 文件夹。
首先,让我们确定应该在什么地方放置调用获取曲目模块的详细信息。我们知道在 track 查询中需要这些信息。但是我们是否应该将调用添加到 track 解析器中?
// EXAMPLE ONLY - should we add the getTrackModules call here in the track resolver?track: async (_, { id }, { dataSources }) => {// get track detailsconst track = await dataSources.trackAPI.getTrack(id);// get module details for the trackconst modules = await dataSources.trackAPI.getTrackModules(id);// shape the data in the way that the schema expects itreturn { ...track, modules };};
我们当然可以这样做。这是我们在 Lift-off II 中面临的一个类似问题,当时我们试图找出在哪里检索每个曲目的作者详细信息。我们最终将该逻辑提取到一个不同的 解析器中: Track.author.
出于完全相同的原因,我们需要对我们的模块详细信息做同样的事情。让我们深入探究原因。
⛓️ 解析链
我们经常会在 GraphQL中看到这种特定的模式。当我们编写 查询时,我们经常有嵌套的对象和 字段。以这个查询为例:
query track(id: ‘c_0') {titleauthor {name}}
请记住,一个 解析器负责在您的架构中填充 字段的数据。它从 数据源中检索数据。在我们的案例中,我们为我们的 track 字段设置了一个解析器,该解析器从 REST API /track/:id终端点检索数据。
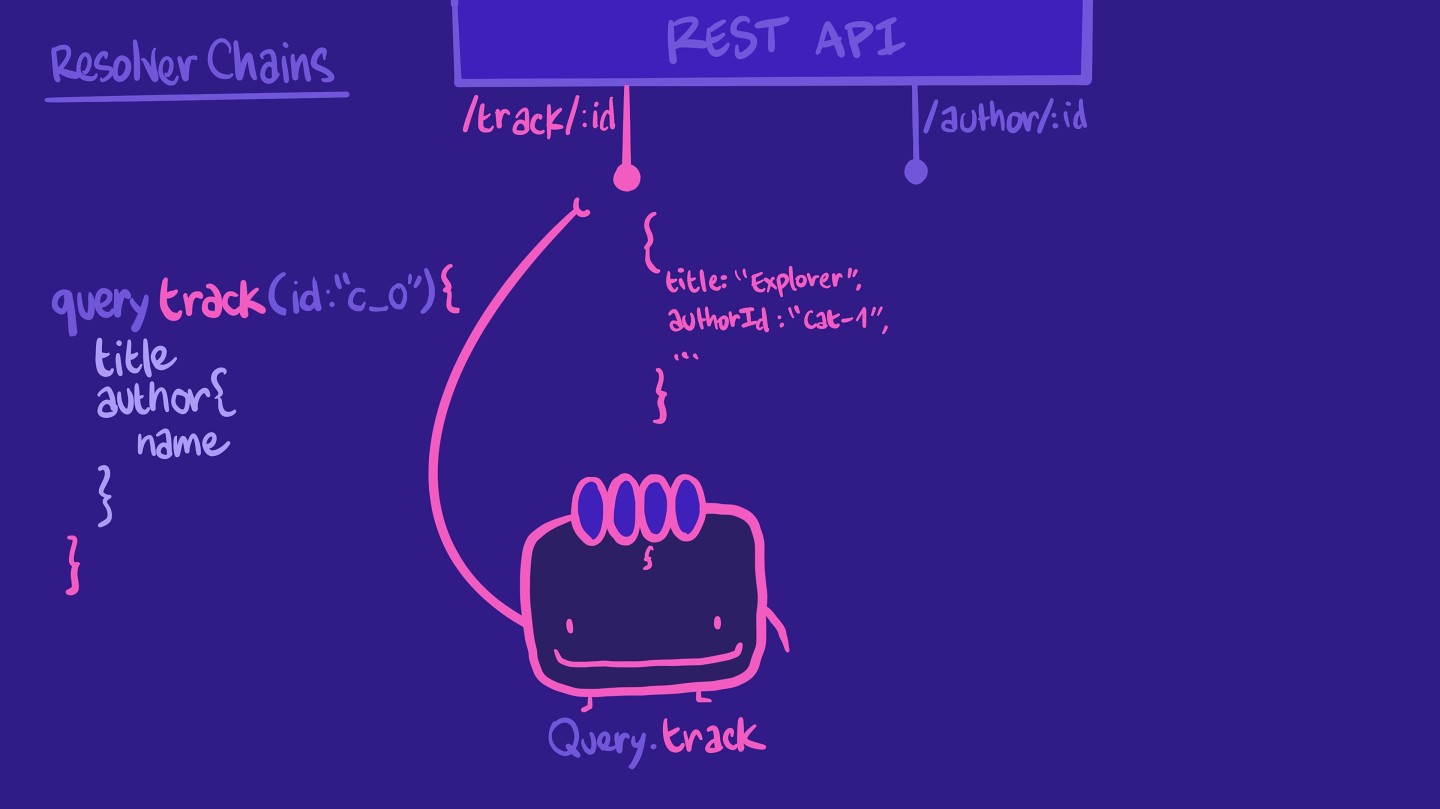
它返回我们的 查询预期的某些属性,例如 title。它没有作者姓名,但它有 authorId,这是一个我们可以用于我们 REST API 中另一个终端点 author/:id终端点的 ID。
我们能够告知这个 相同的 解析器调用 author/:id终端点,然后将结果整合到我们的 查询预期的格式中。
然而,这意味着 解析器有点忙得不可开交了!如果 查询不要求作者信息,那么解析器将 仍然执行所有这些不必要的步骤。
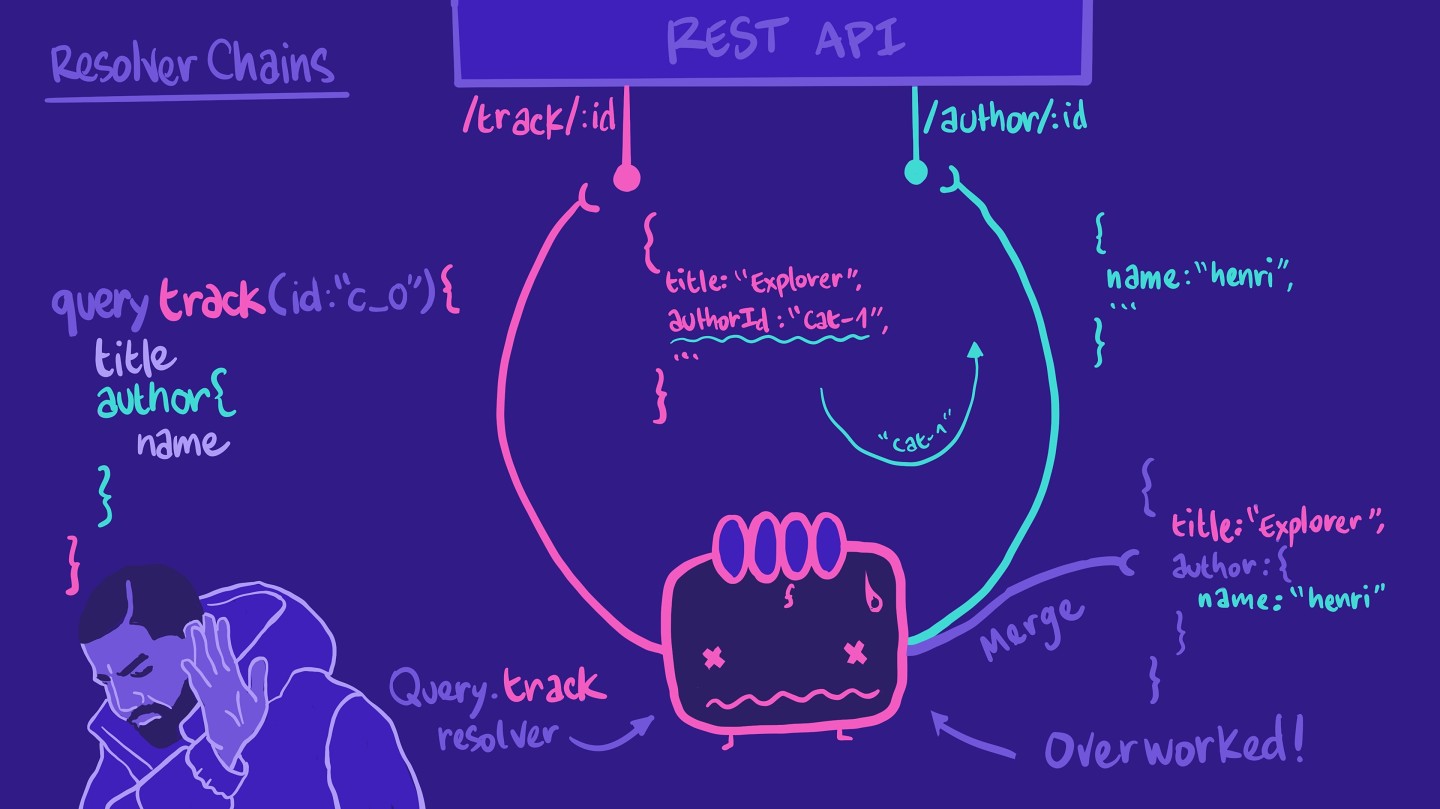
所以,与其把所有工作都交给可怜的 Query.track 解析工具,我们可以为 Track.author创建另一个解析器函数。此 解析工具负责为特定曲目检索作者信息。有了它,我们便形成了一个解析器链!
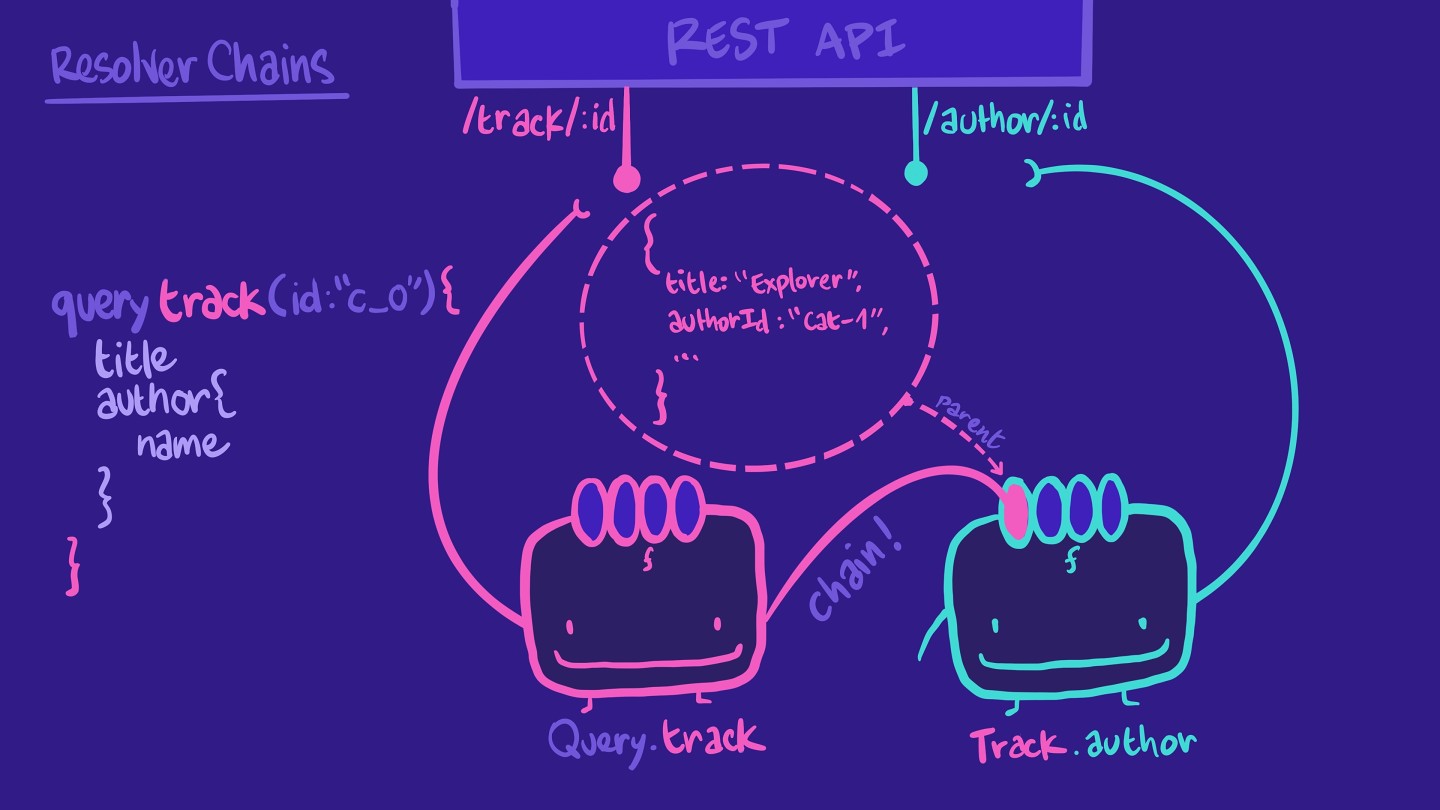
还有 解析工具中的第一个参数—— parent? parent指的是链中前一个 解析工具函数的返回数据!这就是我们如何在 Track.author 解析工具中从 track对象中获取 authorIdauthorId。此外, Track.author 解析工具只会在 查询请求该 字段时才被调用!
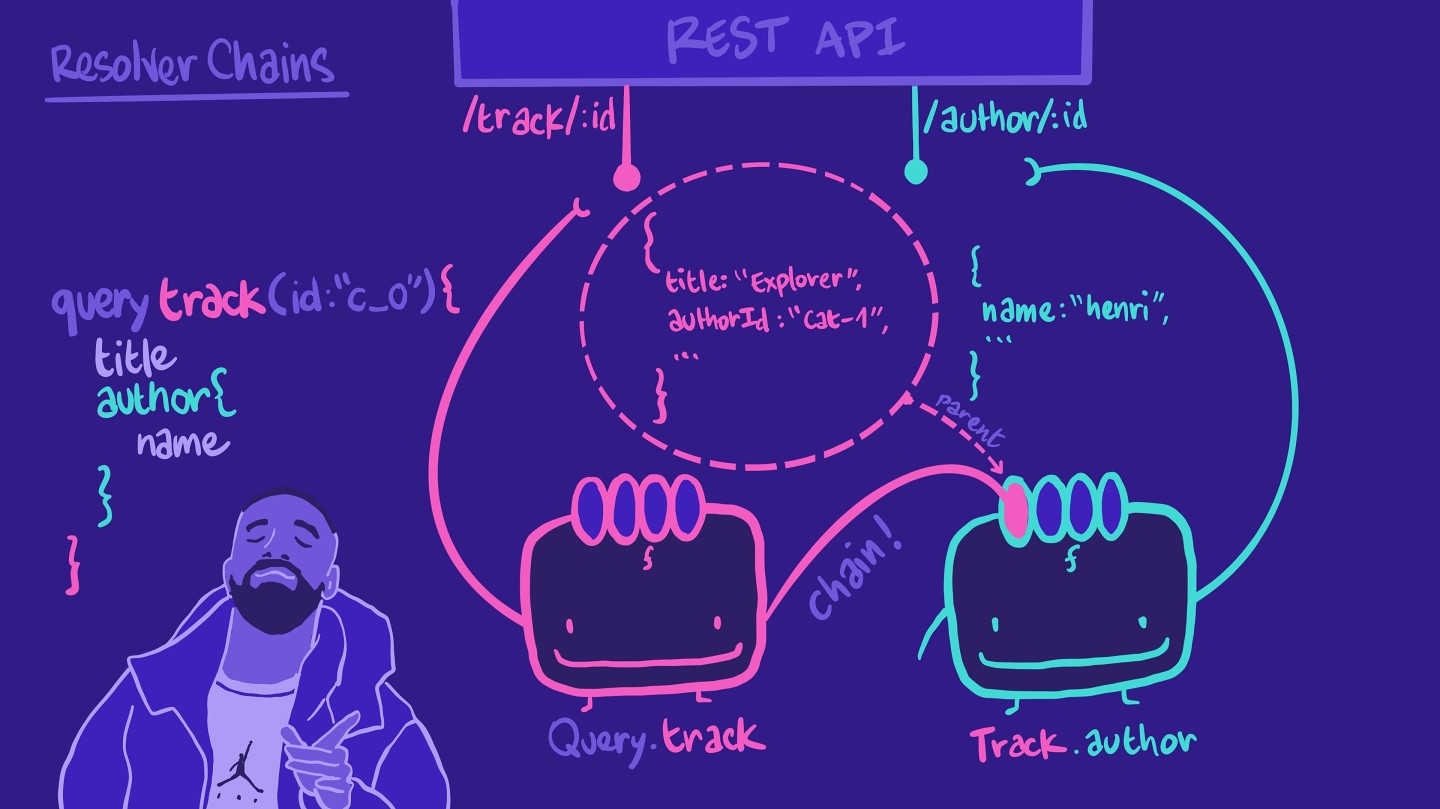
此模式可保持每个 解析工具的可读性、易理解性,还能提高对未来变更的适应性。
args, 是一个包含传递到字段的所有 将此框中的项目拖至上面的空格
解析器链
parent变量
参数
信息数据源
contextValue字段
值
类型
✍️ 向链中添加新的解析器
回到我们特定的问题,让我们使用这个解析器链的概念来为Track.modules创建一个解析器。
我们将在Track.author的下面添加这个解析器在resolvers.js文件中:
modules: ({id}, _, {dataSources}) => {return dataSources.trackAPI.getTrackModules(id);},
我们将解构第一个参数来从父级中检索id属性,它就是跟踪的id。我们不需要那个args参数,因此它可以是一个下划线,然后解构第三个contextValue参数以获取dataSources属性。
在里面,我们可以返回调用我们的dataSources.trackAPI.getTrackModules方法的结果,传入跟踪的id。
这就是我们的解析器所要完成的任务!有了它后,我们已经更新了我们的解析器、数据源和模式,并且准备处理我们的新查询。
分享你对本课程提出的问题和意见
你的反馈可以帮助我们改进!如果你遇到了困难或困惑,请告诉我们,我们会帮助你的。所有评论都是公开的,并且必须遵守 Apollo 行为准则。请注意,已解决或已处理的评论可能会被删除。
你需要拥有 GitHub 帐号才能在下方进行发布。没有 GitHub 帐号? 改为在我们的 Odyssey 论坛中发布。