我们已经实现了我们的解析器和我们的 数据源,并且我们已经把它们连接到了服务器。现在找出所有内容是否一起正常工作以实际提供实时数据。
你可以追踪你的 查询一直到客户端的旅程,并且期望在你的浏览器中看到实时数据,但是实际上有一个秘密捷径来到达服务器端:Apollo Studio Explorer!它让你连接到当前在 localhost:4000运行的服务器,并帮助你快速构建查询进行测试。
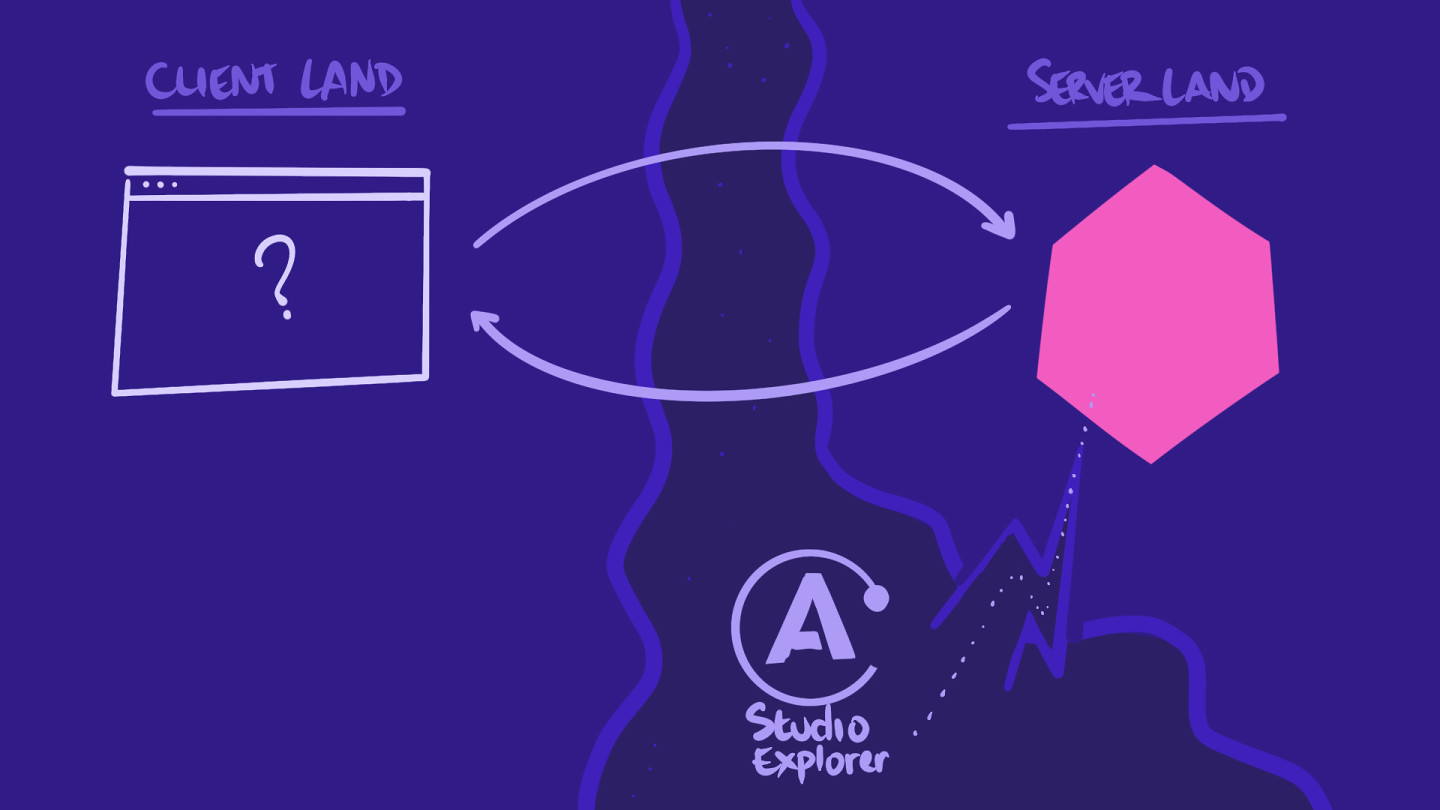
我们的服务器仍然在运行,因此你应该在终端中看到一条消息,指出服务器实际上在运行,并且我们可以使用提供的链接在 Explorer 中开始查询。
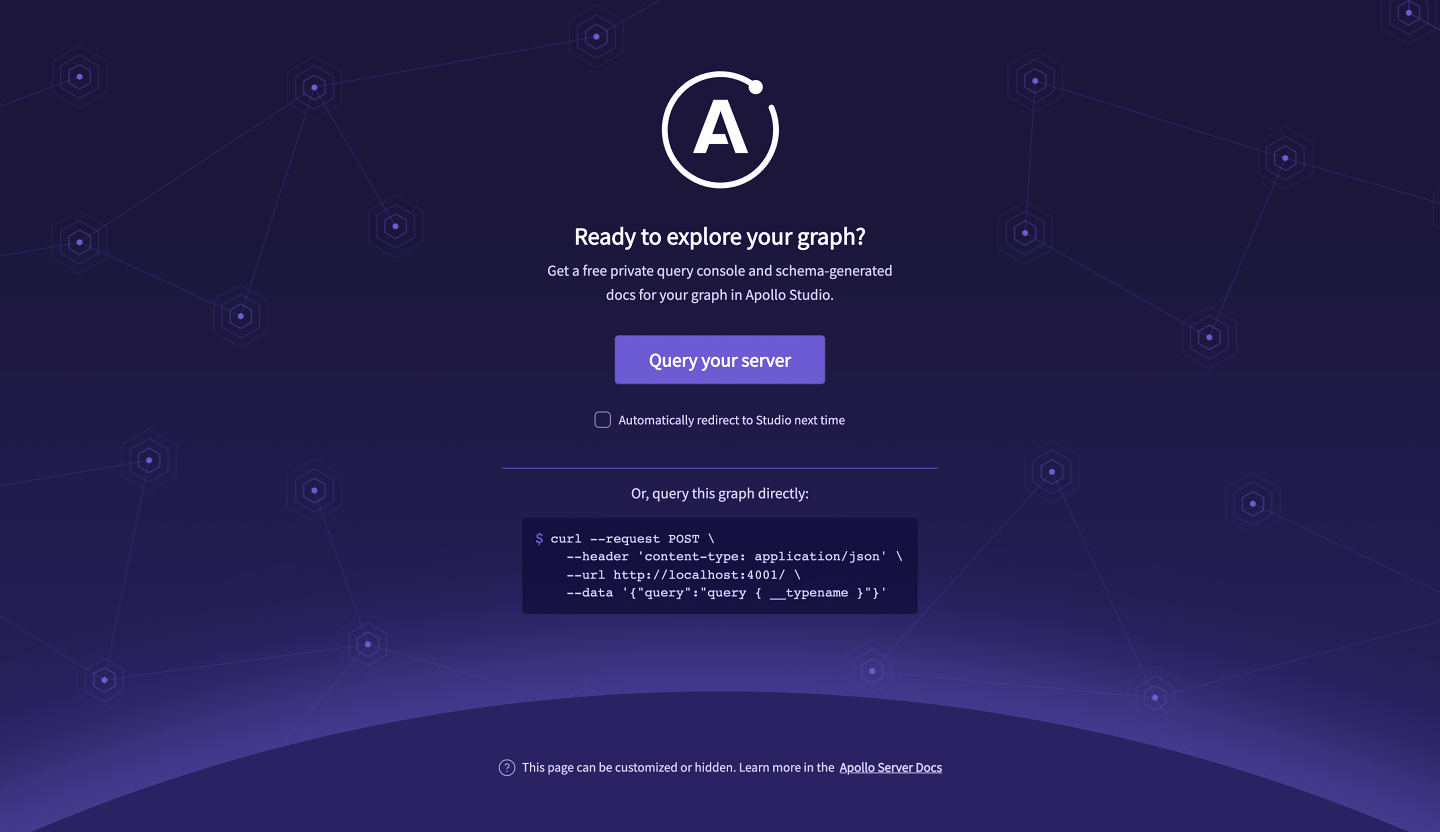
若要在 Apollo Sandbox中打开 Explorer,你可以在终端中 cmd+单击 URL(从启动服务器开始)以在浏览器中打开它,或者你可以在此处打开它:https://:4000。
在浏览器中,我们可以看到我们的服务器正在成功运行,并且有一个消息邀请我们 查询它。我们来单击 查询您的服务器以在 Apollo Sandbox中查看我们的 图的实际执行情况。
我们可以使用来自 Lift-off I 的示例 查询来测试我们的新 解析器:
query GetTracks {tracksForHome {idtitlethumbnaillengthmodulesCountauthor {idnamephoto}}}
我们来执行它... 我们将获得解析器返回的数据! 🎉 我们还可以看到,我们只获得了我们查询的确切数据,没有任何多余的内容,即使我们的 REST 端点没有以这种方式构成。这意味着解析器已完成其任务,而我们也完成了任务!
在 Apollo Studio Explorer 中,测试我们在第 I 部分中使用过的相同 tracksForHome 查询(或复制上述查询并将其粘贴到 Explorer 中)。运行查询,然后将最后一个 tracks 条目复制并粘贴到下面。
让我们再次单击 查询按钮。你是否注意到我们第二次获得响应的速度有多快?第一次大约花了半秒钟,然后第二次只在几毫秒内就返回了。这要归功于我们的 RESTDataSource的内置资源缓存。
仅仅为了对比的乐趣,你可以查看以下fetch实现。我们架构中添加了一个称作tracksforHomeFetch的新字段。该解析器使用node-fetch代替RESTDataSource。对于每个调用,响应都消耗相同的时间,大约半秒。效率大大降低,现在我们真正明白为什么应继续使用RESTDataSource实现!
注意:不要将以下两个代码段复制到你的项目中,你可以在存储库的fetch-example分支中final文件夹中找到完整的提取代码示例。
const typeDefs = gql`type Query {tracksForHome: [Track!]!tracksForHomeFetch: [Track!]!}# ...`;
const resolvers = {Query: {tracksForHome: () => {// ...}tracksForHomeFetch: async () => {const baseUrl = "https://odyssey-lift-off-rest-api.herokuapp.com";const res = await fetch(`${baseUrl}/tracks`);return res.json();},},Track: {// using fetch instead of dataSourcesauthor: async ({ authorId }, _, { dataSources }) => {const baseUrl = "https://odyssey-lift-off-rest-api.herokuapp.com";const res = await fetch(`${baseUrl}/author/${authorId}`);return res.json();// return dataSources.trackAPI.getAuthor(authorId);},},}
RESTDataSource 的查询与使用简单提取方法的查询,我们在资源管理器中展示了其中的哪些内容?分享你对本课程的问题和评论
你的反馈有助于我们改进!如果你遇到困难或困惑,请告知我们,我们将帮你解决。所有评论都是公开的,且必须遵循 Apollo 行为准则。请注意,已解决或处理的评论可能会被移除。
你将需要一个 GitHub 帐户才能在下面发表帖子。没有帐户? 改在我们的 Odyssey 论坛中发表帖子。