我们了解我们数据的位置,并且我们理解其结构。太棒了。现在从我们的解析器!
我们的 GraphQL 服务器需要访问该 REST API。它可以使用 fetch直接调用 API,或者我们可以使用一个名为 DataSource的便捷助手类。此类负责解决直接方法的一些挑战和局限性。

为了更好地理解这些挑战和限制,让我们从 fetch开始,然后再创建一个 DataSource。
在 Node.js 环境中调用 REST API 时,我们可能会使用 axios或 node-fetch之类的库。它们可以轻松访问 HTTP 方法和良好的 async 行为。
使用 node-fetch,从我们的 /tracks 端点检索所有曲目如下所示:
fetch("apiUrl/tracks").then(function (response) {// do something with our tracks JSON});
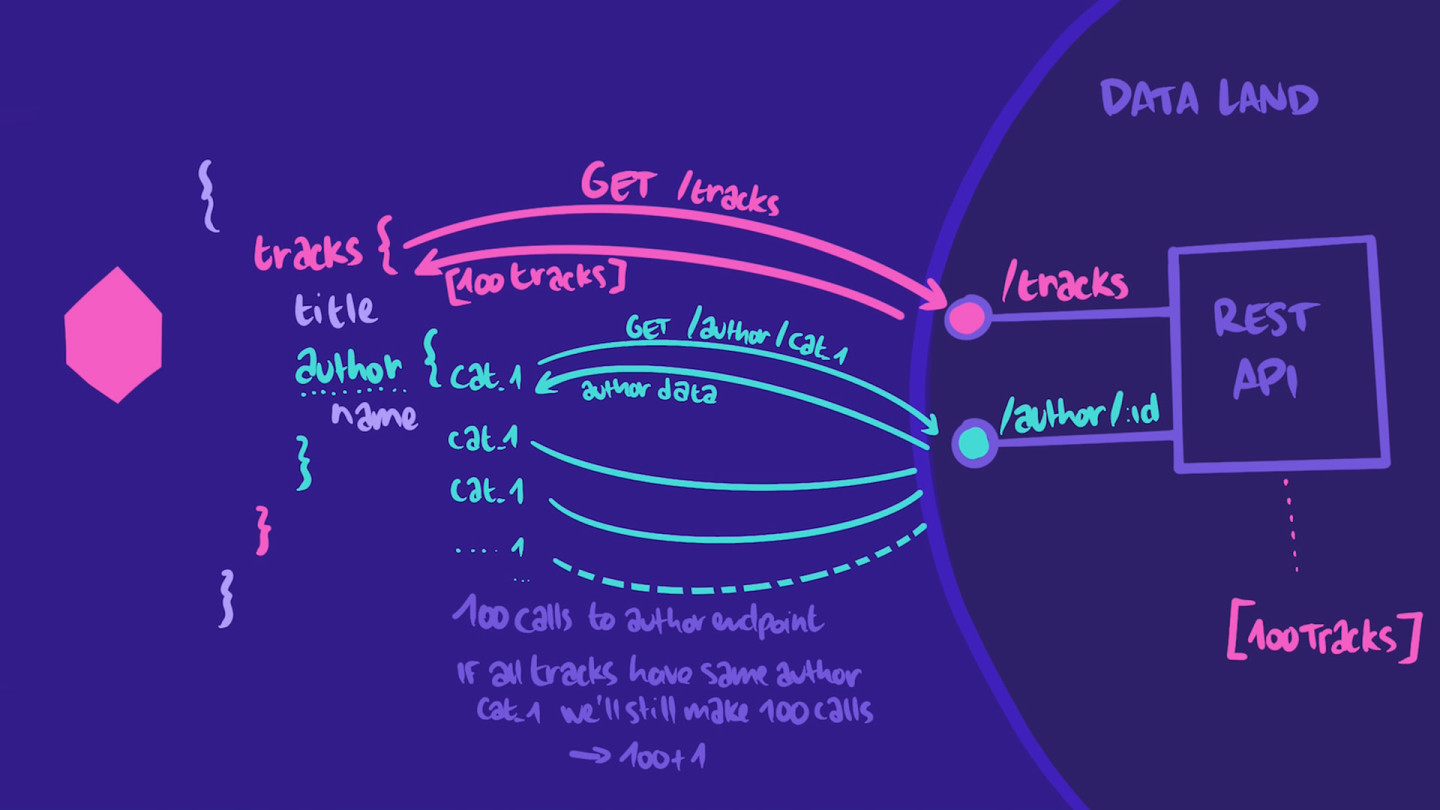
这为我们提供了曲目数组,但我们仍缺少创作信息。对于数组中的每首曲目,我们需要像这样调用 /author/:id 端点:
fetch(`apiUrl/author/${authorId}`).then(function (response) {// this is the author of our track});
假设我们的 /tracks 端点返回 100 首曲目。然后,我们将运行一次调用以获取数组,然后运行 100 次附加调用 以获取每首曲目的创作信息。
现在,如果我们的 100 首曲目均由同一位创作者创作,该怎么办?我们将运行一次调用以获取曲目,检索到 100 首曲目,然后运行 100 次调用以获取完全相同的创作信息。
听起来非常低效,是吗?我们最终将运行 101 次调用,而实际只需要运行两次。
这是一个 N+1 问题的经典示例。“1”是指调用以获取顶级 tracks 字段,“N”是为每首曲目获取创作子字段而进行的后续调用次数。
{tracks {# 1titleauthor {# N calls for N tracksname}}}
此外,在我们的应用和此特定 查询的上下文中,我们不希望主页非常频繁地改变。可能每隔几周会新增一首曲目。最好利用缓存来避免对我们的 REST API 进行不必要的调用。很方便的是,我们的 REST API 已为其端点设置了缓存标头。
使用 GraphQL,一个 查询通常由来自不同端点、具有不同缓存策略的不同 字段和类型组成。那么,我们如何在这样的上下文中处理缓存?
我们开始真正地感受到简单fetch方法的限制。
要解决这些问题,我们需要专门为GraphQL设计的某些内容,可以有效地处理 REST API 调用中的资源缓存和重复数据删除。
而且,在构建GraphQLAPI 时,从 REST 中获取数据是一项非常常见的任务,因此 Apollo 提供了一个RESTDataSource类,专门用于此目的:RESTDataSource,
通过在服务器上实现RESTDataSource,我们刚刚看到的的挑战已经得到妥善解决。
我们来看在 Catstronauts 应用中如何扩展和实现此RESTDataSource。
分享你对本课提出的问题和想法
你的反馈有助于我们改进服务!如果你遇到困难或感到困惑,请告诉我们。所有评论都是公开的,必须遵守 Apollo 行为准则。请注意,已解决或处理的评论可能已删除。
在下方发帖,你需要一个 GitHub 帐户。没有帐户? 改发帖到我们的 Odyssey 论坛。