Apollo Client中的缓存
概述
Apollo Client 将您的 GraphQL 查询结果存储在一个本地、规范化、内存中的缓存中。这使得 Apollo Client 可以几乎立即响应对已缓存数据的查询,即使不发送网络请求。规范化,Apollo Client 可以响应几乎立即对已缓存数据的查询,无需发送网络请求。
例如,第一次您的应用程序执行一个 首次 对具有 idGetBook 查询,针对 id 5 的 Book 对象,流程如下:
并且在您的应用程序对于该相同对象执行的 每次 GetBook 后继查询,流程如下:
Apollo Client 缓存高度可配置。您可以为单个类型和 字段 在您的模式中自定义其行为,并且您甚至可以使用它来存储和交互与本地数据,这些数据 不 是从您的 GraphQL 服务器获取的。
数据是如何存储的?
Apollo客户端的's InMemoryCache存储数据为一个扁平的查找表,其中对象可以相互引用。这些对象对应于您通过GraphQL查询返回的对象。单个缓存的物件可能包含多个查询返回的字段,如果这些查询检索不同 字段的同一个对象。
虽然缓存是扁平的,但GraphQL查询返回的对象通常不是!实际上,它们的嵌套可以任意深。以下是一个查询响应示例:
{"data": {"person": {"__typename": "Person","id": "cGVvcGxlOjE=","name": "Luke Skywalker","homeworld": {"__typename": "Planet","id": "cGxhbmV0czox","name": "Tatooine"}}}}
此响应包含一个Person对象,该对象反过来在其
那么,InMemoryCache如何在一个扁平的查找表中存储嵌套数据?在存储此数据之前,缓存需要对其norm化。
数据标准化
每当Apollo客户端缓存收到查询响应数据时,它会执行以下操作:
1. 识别对象
首先,缓存识别查询响应中包含的所有不同的对象。在上面的示例中,有两个对象:
- 一个具有
idcGVvcGxlOjE= - 一个
行星,其idcGxhbmV0czox
2. 生成缓存ID
识别所有对象后,缓存为每个对象生成一个 缓存ID。缓存ID在 InMemoryCache 中唯一标识特定对象。
默认情况下,对象的缓存ID是对象的 __typename 和 id(或 _id)字段的连接,由冒号(:)分隔。
因此,上述示例中对象的默认缓存ID为:
Person:cGVvcGxlOjE=Planet:cGxhbmV0czox
您可以自定义特定 对象类型 的缓存ID格式。请参阅 自定义缓存ID。
如果缓存 无法生成特定对象的缓存ID(例如,如果没有 id 或 _id 字段),则该对象将直接缓存在其 父对象中,并且必须通过父对象引用(这意味着缓存不总是 完全扁平的)。
3. 替换对象字段为引用
接下来,缓存有两个包含对象的字段,并替换其值以适当的对象引用。
例如,以下是上述示例中的 Person对象在引用替换 之前的状态:
{"__typename": "Person","id": "cGVvcGxlOjE=","name": "Luke Skywalker","homeworld": {"__typename": "Planet","id": "cGxhbmV0czox","name": "Tatooine"}}
以下是引用替换 之后的同一个对象:
{"__typename": "Person","id": "cGVvcGxlOjE=","name": "Luke Skywalker","homeworld": {"__ref": "Planet:cGxhbmV0czox"}}
当前 homeworld 字段现在包含对适当的标准化 Planet 对象的引用。
如果上一步骤没有为该对象生成缓存ID,则不会替换特定对象的某些字段。相反,原始对象保持不变。
稍后,如果您 查询具有相同 家庭世界 的另一个 Person,该标准化 Person 对象将包含对 相同的 已缓存对象的引用! 标准化 可以显着减少数据重复,并且还有助于使本地数据与服务器保持同步。
4. 存储标准化对象
最后,生成的所有对象都存储在缓存的平面查找表中。
任何进入的对象,如果其缓存ID与现有缓存的缓存ID相同,这些对象的字段将
- 如果传入的对象和现有对象共享任何字段,传入的对象将覆盖那些字段的缓存值。
- 字段只出现在现有对象或传入对象中的字段会被保留。
规范化将构建您客户端上部分图的部分副本,该格式针对您的应用程序状态发生变化时进行读取和更新进行了优化。
可视化缓存
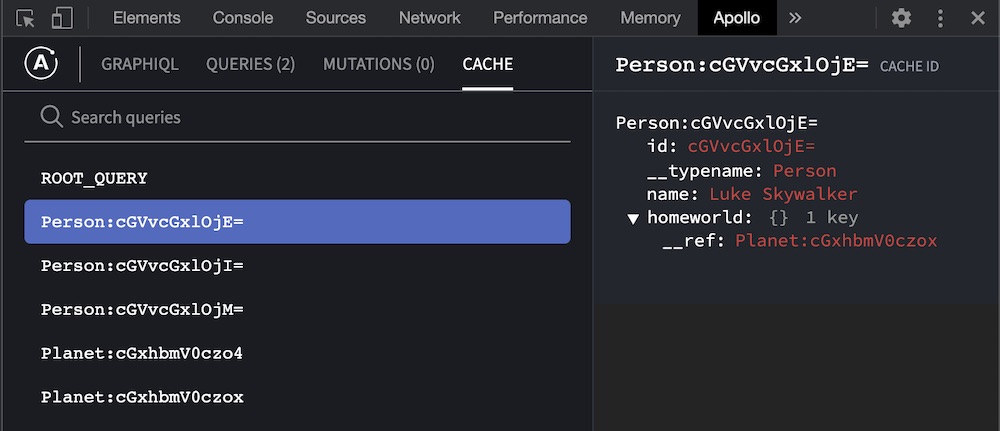
为了帮助理解您缓存数据的结构,我们强烈建议安装 Apollo Client Devtools。
这个浏览器扩展包含一个检查器,您可以使用它查看缓存中包含的所有规范化对象
示例
假设我们使用 Apollo Client 运行以下 查询 在 SWAPI demo API:
query {allPeople(first:3) { # Return the first 3 itemspeople {idnamehomeworld {idname}}}}
此 查询 返回以下三个 Person 对象的结果,每个对象都有一个相应的 homeworld(一个 Planet 对象):
注意,结果中的每个对象都包含一个 __typename 字段,尽管我们的 查询 字符串 没有包含这个字段。这是因为 Apollo Client 自动查询每个对象的 __typename。
结果被缓存后,我们可以在 Apollo Client Devtools 中查看我们缓存的已知状态:
我们的缓存现在包含五个规范化的对象(除了ROOT_QUERY对象之外):三个Person对象和两个Planet对象。
为什么我们只有两个Planet对象?因为有两个人Person对象有相同的homeworld。通过像这样规范化数据,Apollo Client可以缓存单一对象副本,并用多个其他对象包含对它的引用(见上面截图中的对象__ref字段)。
下一步
现在,你对Apollo Client's 缓存工作原理有了基本了解后,了解如何配置它。
然后,你可以学习如何直接读取和写入缓存中的数据,而不必针对您的服务器执行查询。这是一个强大的本地状态管理选项。