在 Apollo 客户端中使用缓存的进阶主题
本文描述了使用Apollo 客户端缓存时的特殊情况和注意事项。
绕过缓存
有时候你不应该为特定GraphQL操作使用缓存。例如,查询的响应可能是一次性使用的令牌。在这种情况下,使用无缓存获取策略:
const { loading, error, data } = useQuery(GET_DOGS, {fetchPolicy: "no-cache"});
操作使用此获取策略不将结果写入缓存,在向服务器发送请求之前,它们也不检查缓存中的数据。查看所有可用的获取策略。
持久化缓存
您可以从AsyncStorage或localStorage之类的存储提供程序持久化和重新激活InMemoryCache。为此,请使用apollo3-cache-persist库。这个库可以与各种存储提供程序协同工作。
要开始,请将您的缓存和存储提供程序传递给persistCache。默认情况下,您的缓存的任何内容都会异步立即恢复,并且每当写入缓存时,都会以可配置的短暂延迟时间持久化。
ⓘ 注意
《persistCache метод является асинхронным и возвращает Promise。
import AsyncStorage from '@react-native-async-storage/async-storage';import { InMemoryCache } from '@apollo/client';import { persistCache } from 'apollo3-cache-persist';const cache = new InMemoryCache();persistCache({cache,storage: AsyncStorage,}).then(() => {// Continue setting up Apollo Client as usual.})
有关高级使用和更多配置选项,请查看README of apollo3-cache-persist。
重置缓存
有时,您可能希望完全重置缓存,例如当用户注销时。为此,请调用client.resetStore。此方法异步,因为它还会重新查询任何活动的查询。
import { useQuery } from '@apollo/client';function Profile() {const { data, client } = useQuery(PROFILE_QUERY);return (<Fragment><p>Current user: {data?.currentUser}</p><button onClick={async ()=>client.resetStore()}>Log out</button></Fragment>);}
要重置缓存而不重新查询活动查询,请使用client.clearStore()而不是client.resetStore()。
响应缓存重置
您可以为client.resetStore的调用注册回调函数。为了实现这一点,请调用client.onResetStore并传入您的回调函数。要注册多个回调函数,请多次调用client.onResetStore。所有回调函数都添加到一个数组中,并在缓存重置时并发执行。
在本示例中,我们使用client.onResetStore将默认值写入缓存。这对于使用Apollo Client的本地状态管理功能并在应用程序的任何位置调用client.resetStore非常有用。
import { ApolloClient, InMemoryCache } from '@apollo/client';import { withClientState } from 'apollo-link-state';import { resolvers, defaults } from './resolvers';const cache = new InMemoryCache();const stateLink = withClientState({ cache, resolvers, defaults });const client = new ApolloClient({cache,link: stateLink,});client.onResetStore(stateLink.writeDefaults);
您还可以从React组件中调用client.onResetStore。如果您想在缓存重置后强制UI重新渲染,这将非常有用。
client.onResetStore方法返回一个函数,您可以调用它来注销您的回调:
import { useApolloClient } from '@apollo/client';function Foo (){const [reset, setReset] = useState(0);const client = useApolloClient();useEffect(() => {const unsubscribe = client.onResetStore(() =>new Promise(()=>setReset(reset + 1)));return () => {unsubscribe();};});return reset ? <div /> : <span />}export default Foo;
类型策略继承
JavaScript开发者可能会熟悉从继承从类声明的extends子句中熟悉,或者可能从与Object.create创建的原型链交互中熟悉。
继承是一种强大的代码共享工具,并且它与Apollo Client协同工作有以下几个原因:
InMemoryCache已经知道了您模式中的超类型-子类型关系(接口和联接),这是因为possibleTypes,所以不需要额外的配置来提供这些信息。继承允许超类型为其所有的子类型提供默认配置值,包括
keyFields和单个字段策略。这些值可以被需要不同设置的自定义子类型选择性地覆盖。一个子类型可以在GraphQL模式中有多个超类型,这是使用类或原型的单一继承模型难以建模的。换句话说,在JavaScript中支持多继承需要构建一个类似的系统,而不是仅仅重用内置语言功能。
开发者可以通过将它们自己的客户端专用超类型添加到
possibleTypes映射中,作为在类型之间重用行为的一种方式,即使它们的模式对那些超类型一无所知。possibleTypes映射目前仅用于片段匹配目的,这是客户端所做的非常重要的但相对较小的一部分。继承为
possibleTypes添加了另一个令人信服的使用案例,并且当有效使用时应该极大地减少typePolicies的重复。
以下是如何为 InMemoryCache 实现类型策略继承的方法,以下为示例:
const cache = new InMemoryCache({possibleTypes: {Reptile: ["Snake", "Turtle"],Snake: ["Python", "Viper", "Cobra"],Viper: ["Cottonmouth", "DeathAdder"],},typePolicies: {Reptile: {// Suppose all our reptiles are captive, and have a tag with an ID.keyFields: ["tagId"],fields: {// Scientific name-related logic can be shared among Reptile subtypes.scientificName: {merge(_, incoming) {// Normalize all scientific names to lower case.return incoming.toLowerCase();},},},},Snake: {fields: {// Default to a truthy non-boolean value if we don't know// whether this snake is venomous.venomous(status = "unknown") {return status;},},},},});
突变后重新获取查询
在某些情况下,编写一个 update 函数来在突变后更新缓存可能很复杂,甚至如果突变没有返回修改后的字段则根本无法实现。
在这种情况下,您可以将 refetchQueries 选项提供给 useMutation 钩子,以在突变完成后自动重新运行某些查询。
有关详细信息,请参阅 重新获取查询。
ⓘ 注意
虽然 refetchQueries 可以比 update 函数更快地实现,但它也需要额外的网络请求,这通常是不希望看到的。更多信息请参见 这篇博客文章。
缓存重定向
在某些情况下,一个 查询 请求的数据已存在缓存中,但引用不同。例如,您的 UI 可能有一个列表视图和详细视图,它们都使用相同的数据。
列表视图可能运行以下 查询:
query Books {books {idtitleabstract}}
选择特定的书籍时,详情视图可能会使用以下查询显示单个项目:
query Book($id: ID!) {book(id: $id) {idtitleabstract}}
在这种情况下,我们知道第二个查询的数据可能已经存在于缓存中,但因为这个数据是由不同的查询检索的,Apollo Client不知道这一点。要告诉Apollo Client在何处查找缓存中的Book对象,我们可以为book字段定义一个读取策略read函数:
import { ApolloClient, InMemoryCache } from '@apollo/client';const client = new ApolloClient({cache: new InMemoryCache({typePolicies: {Query: {fields: {book: {read(_, { args, toReference }) {return toReference({__typename: 'Book',id: args.id,});}}}}}})});
此read函数使用toReference辅助实用工具生成并返回一个缓存引用针对Book对象,基于其__typename和id。
现在每当查询包含book字段,上面提到的读取函数将执行并返回一个针对Book对象的引用。Apollo Client使用此引用在缓存中查找对象,并在找到时返回它。如果没有找到,Apollo Client知道它需要通过网络执行查询。
ⓘ 注意
为了避免网络请求,查询请求的所有字段必须已存在于缓存中。如果详情视图的查询检索了列表视图的查询没有的任何Book字段,,Apollo Client会认为缓存命中是不完整的,并执行完整的查询通过网络。
分页实用工具
由于几个原因,分页是GraphQL的最佳实践。Apollo Client启用使用核心分页API检索和缓存分页结果。API包括一些重要的实用工具,包括fetchMore函数和@connection指令。
增量加载:fetchMore
您可以使用fetchMore函数使用后续查询返回的数据更新查询的缓存结果。通常,fetchMore用于处理无限滚动分页和您已经有数据时加载更多数据的情况。
有关详细信息,请参阅fetchMore函数。
@connection指令
@connection指令解决了在缓存中存在相同字段的多个副本的问题。这在使用分页查询时可能会发生,因为fetchMore函数会发送后续查询以使用参数(如offset和limit)来获取额外结果页。这些参数意外地将不同分页请求的数据片段化。
@connection指令允许您通过指定字段的一个自定义、稳定的缓存键来统一分页结果。它还可以让您通过指定的字段在缓存中故意分离分页结果。
💡 提示
从Apollo Client v3开始,设置keyArgs字段策略是解决缓存中分页结果片段化问题的最直接方法。例如,将keyArgs设置为false表示不应将任何参数包括在缓存键中,这将导致所有分页结果一起缓存。此外,您只需要一次设置您的keyArgs配置,而不是在多个查询中使用@connection。以下的使用说明列出了如何比较@connection和keyArgs的使用。
当您希望按查询和字段存储缓存中的不同数据时,@connection指令非常有用。有关更详细的信息,请参阅高级使用说明。
@connection 指令使用
💡 提示
在本节中描述的标准的@connection指令使用,最好配置一个keyArgs字段策略。例如,您可以使用以下keyArgs配置来获得与下面@connection示例相同的效果。
const cache = new InMemoryCache({typePolicies: {Query: {fields: {feed: {keyArgs: ["type"]}}}}})
使用这种集中式 keyArg 配置,您不需要在查询中包含 @connection 指令,因为 type 参数 充足以在缓存中将不同类型的流分开。有关按查询基数存储不同数据的示例,请参阅 高级使用说明。
要使用 @connection 指令,将它添加到您想要为其自定义缓存键的字段。该指令需要一个 key 参数来指定自定义缓存键。您可以选则性包含 filter 参数,该参数接受一个查询 参数名 数组,以包含在生成的自定义缓存键中。
const query = gql`query Feed($type: FeedType!, $offset: Int, $limit: Int) {feed(type: $type, offset: $offset, limit: $limit) @connection(key: "feed", filter: ["type"]) {...FeedEntry}}`
在上述 查询 中,即使是执行多个 fetchMore 查询,每次流更新都会导致缓存 feed 键更新到最新累积的值。该示例还使用了 @connection 指令的选则性 filter 参数,将 type 查询 参数 包含在缓存键中。这创建了一组多个缓存值,它们累积每种类型 feed 的查询。
使用稳定的缓存键,您可以使用 writeQuery 来执行清除 feed 的缓存更新的操作。
client.writeQuery({query: gql`query Feed($type: FeedType!) {feed(type: $type) @connection(key: "feed", filter: ["type"]) {id}}`,variables: {type: "top",},data: {feed: [],},});
ⓘ 注意
因为此示例使用缓存键中的 type 参数,因此不需要提供 offset 或 limit 参数。
高级 @connection 指令使用
当在多个查询中使用相同的 字段,且没有可区分 参数(例如,type)供 keyArgs 使用时,以及您希望在不区分不同数据的情况下将缓存中该字段的数据分开,@connection 指令非常有用。
例如,Apollo的 Spotify 示范 使用 @connection 以独立缓存播放列表的列表。一个列表在左侧边栏中,您可以通过该边栏在不同播放列表之间导航。另一个列表在您右键单击歌曲以将其添加到播放列表时出现。
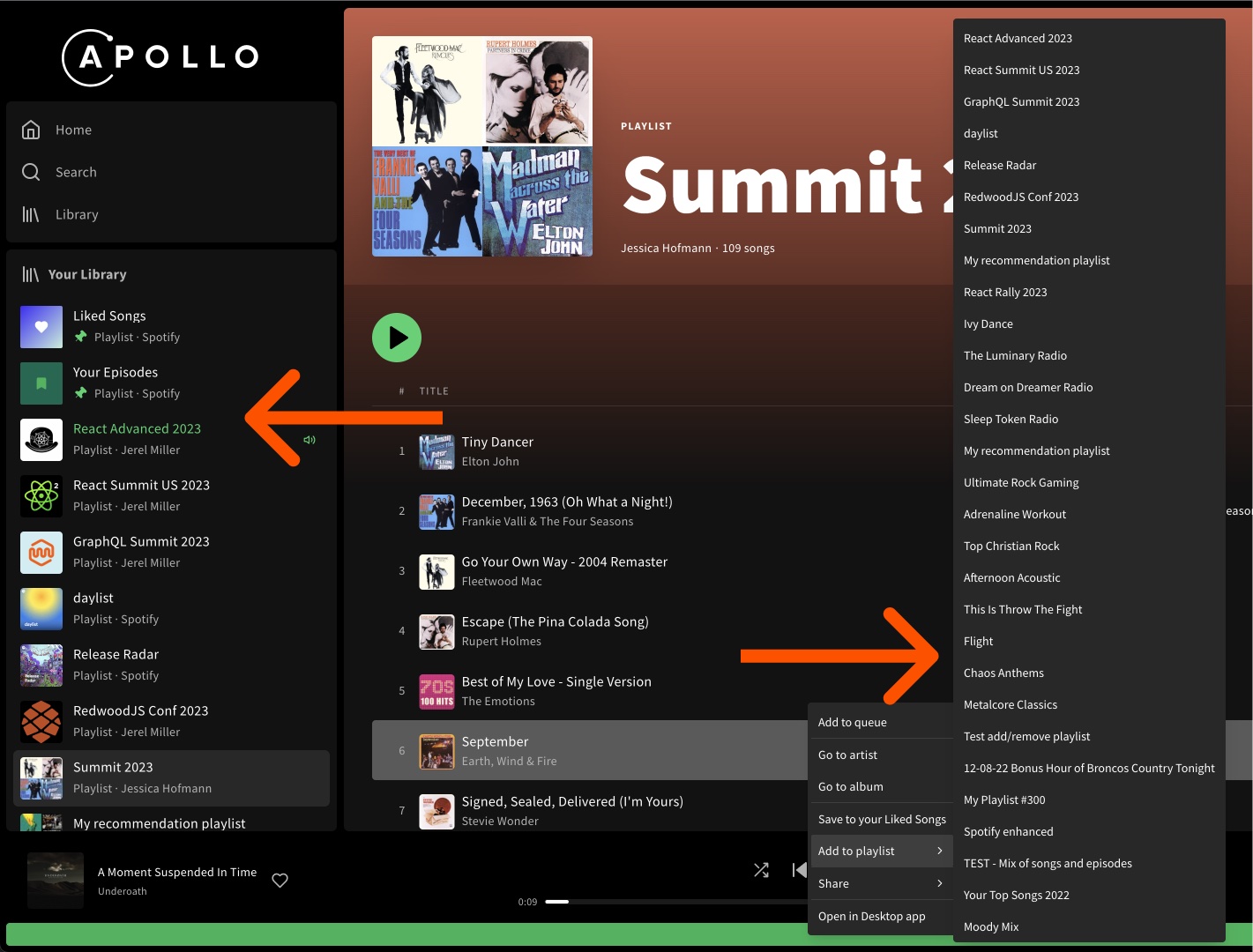
如果不单独缓存播放列表,则一个列表加载数据的下一页将影响另一个列表,从而对用户体验产生负面影响。
有关代码示例,请参阅