📥 获取模块详情
要获取给定轨道的模块详情,我们需要使用GET track/:id/modules端点在我们的REST API中。
让我们再次尝试此端点,给它我们的轨道ID c_0。
我们得到的响应是我们需要的模块详情数组。
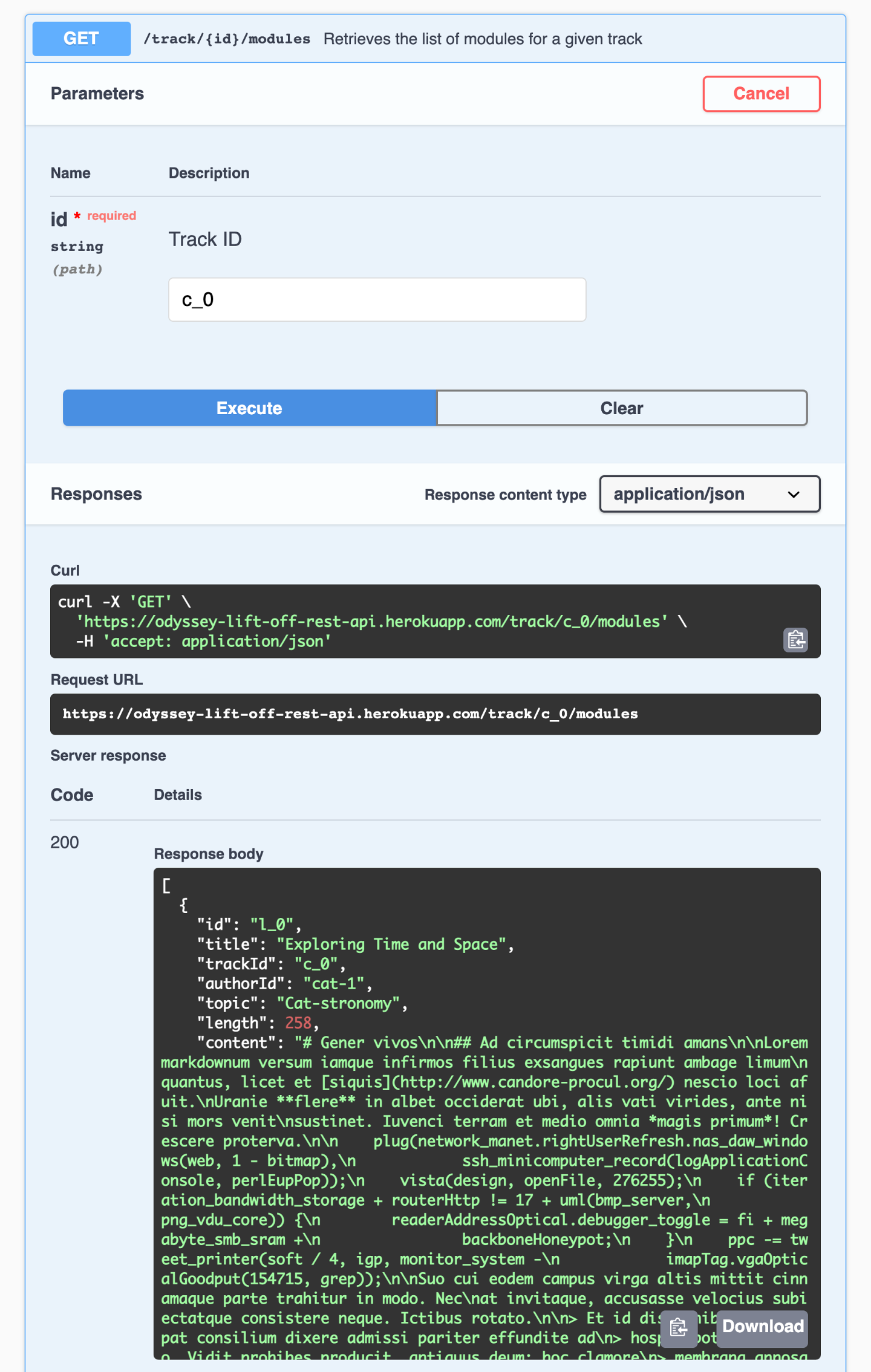
目前,我们的轨道页面需要id、title和length。让我们更新我们的TrackAPI以调用此端点。
💾 更新RESTDataSource
在server/src/datasources文件夹中,打开track-api.js文件。
让我们创建一个名为getTrackModules的方法。它接受一个参数trackId。在内部,它会对track/${trackId}/modules端点进行
getTrackModules(trackId) {return this.get(`track/${trackId}/modules`);}
现在我们可以使用这个新的数据源方法在我们的resolver中。让我们回到resolvers.js文件,该文件位于server/src文件夹中。
首先,我们需要确定我们可以在哪里放置获取歌曲模块详情的调用。我们知道我们需要在track query中获取这些信息。但我们是否应该在track resolver中添加调用?
// EXAMPLE ONLY - should we add the getTrackModules call here in the track resolver?track: async (_, { id }, { dataSources }) => {// get track detailsconst track = dataSources.trackAPI.getTrack(id);// get module details for the trackconst modules = await dataSources.trackAPI.getTrackModules(id);// shape the data in the way that the schema expects itreturn { ...track, modules };};
我们当然可以。这与我们在Lift-off II中遇到的相似问题一样,当时我们试图找出在哪里检索每个歌曲的作者详情。我们最终将逻辑提取到了另一个resolver:Track.author。
出于相同的原因,我们在这里也希望对模块详情做同样的事情。让我们深入探讨一下为什么会这样做。
⛓️ resolver链
我们经常在GraphQL中看到这种模式。当我们编写query时,我们经常有嵌套的对象和fields。以下是一个查询示例:
query track(id: ‘c_0') {titleauthor {name}}
请记住,在你的数据模型中,一个解析器负责获取字段的数据。它从数据源检索数据。在我们的例子中,我们有一个为我们track字段的解析器,该解析器从REST API端点/track/:id获取数据。
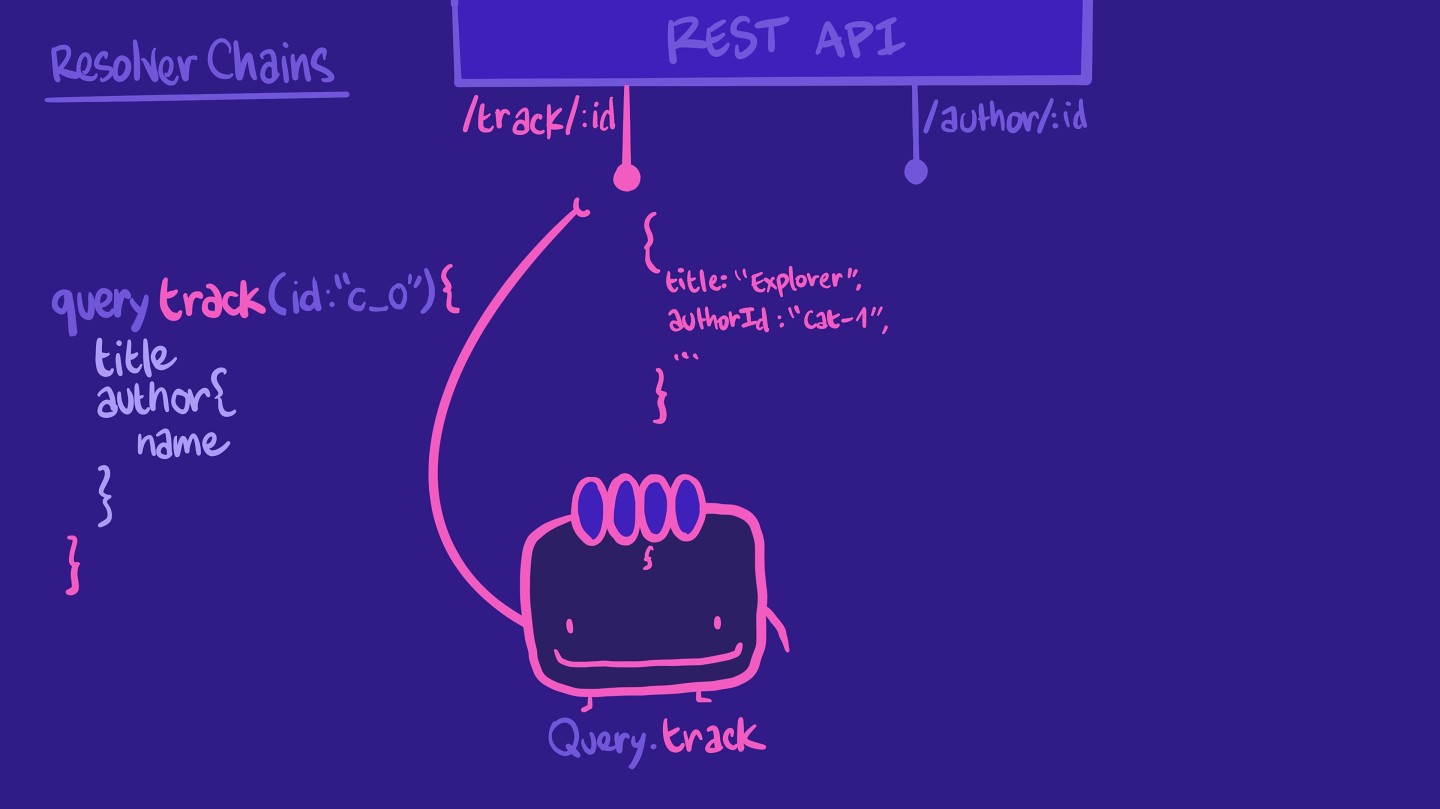
它返回了一些我们查询期望的一些属性,例如title。它没有作者姓名,但有authorId,这是我们可以在REST API中的另一个端点author/:id使用的ID。
我们可以指示这个相同的解析器调用author/:id端点,然后组合成我们的查询期望的形状。
然而,这意味着解析器有点过于繁忙了!如果查询没有要求作者信息,解析器还是依然会执行所有这些不必要的步骤。
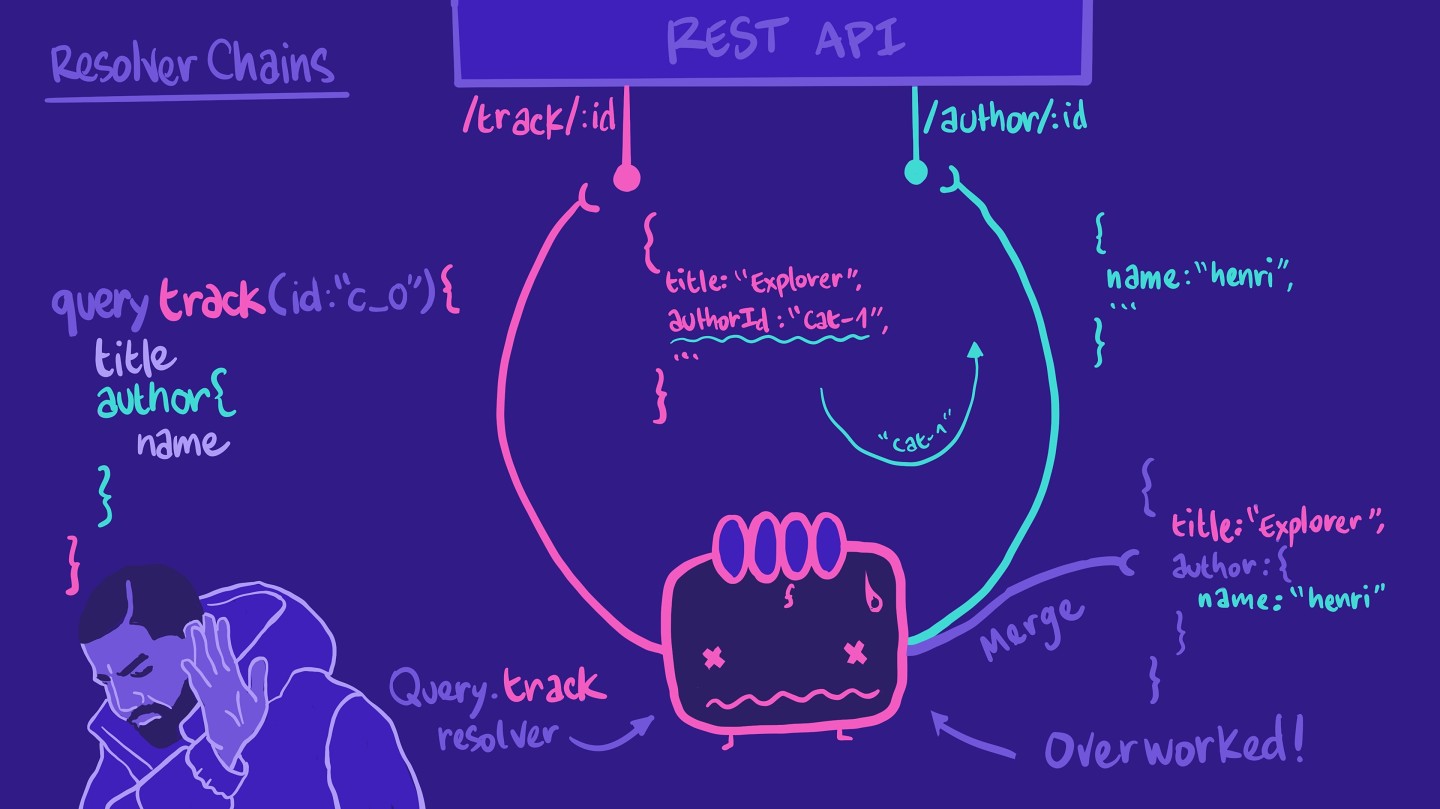
因此,我们不必把这个工作放在我们可怜的Query.track解析器上,我们可以为Track.author创建另一个解析器函数。这个解析器负责检索特定轨道的作者信息。有了这些,我们就在形成一个解析器链!
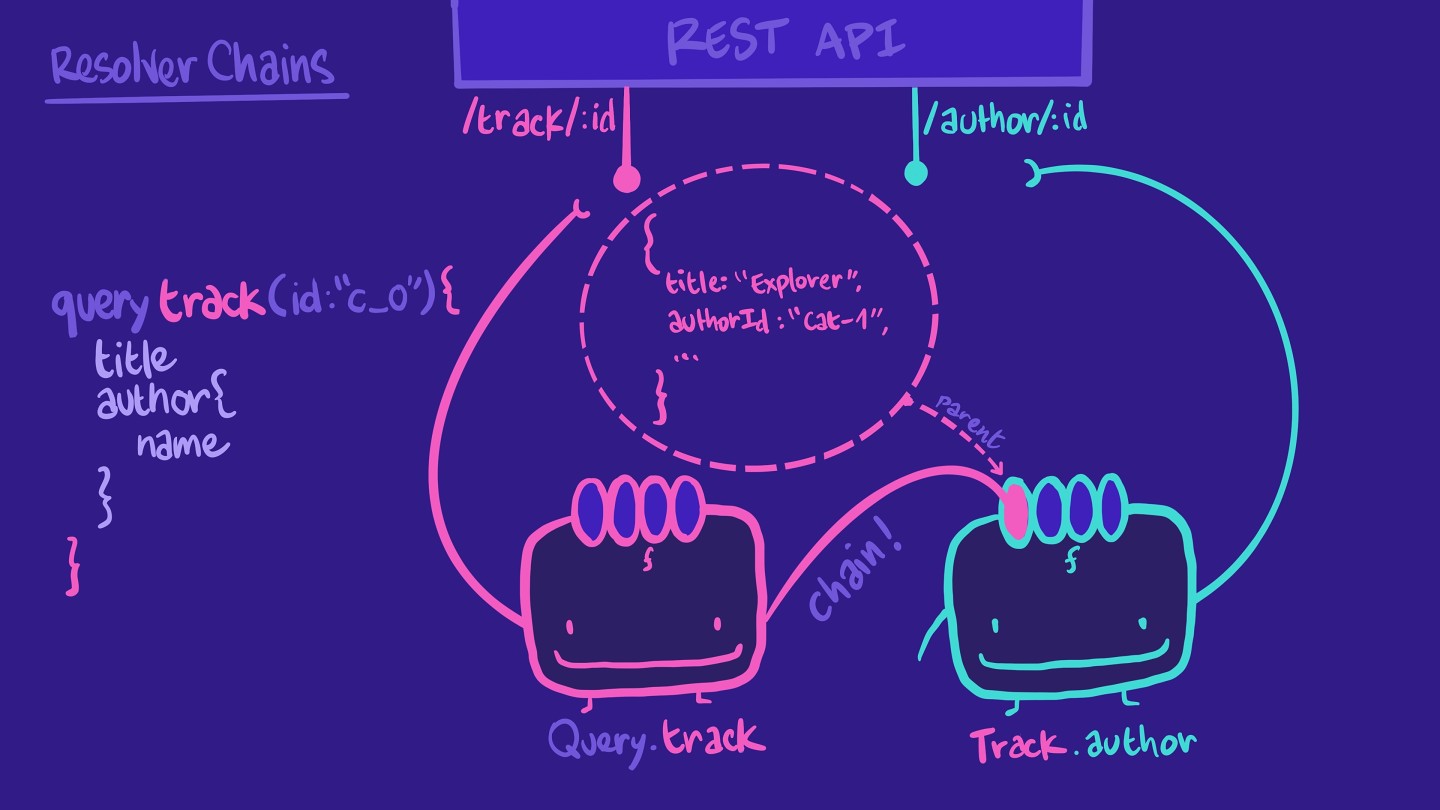
记得解析器的第一个参数——解析器中的parent?,其中parent指的是链中先前的解析器函数返回的数据!这是我们怎样访问Track.author解析器中的authorId从track对象的例子。此外,Track.author解析器只有在查询请求该字段时才会被调用!
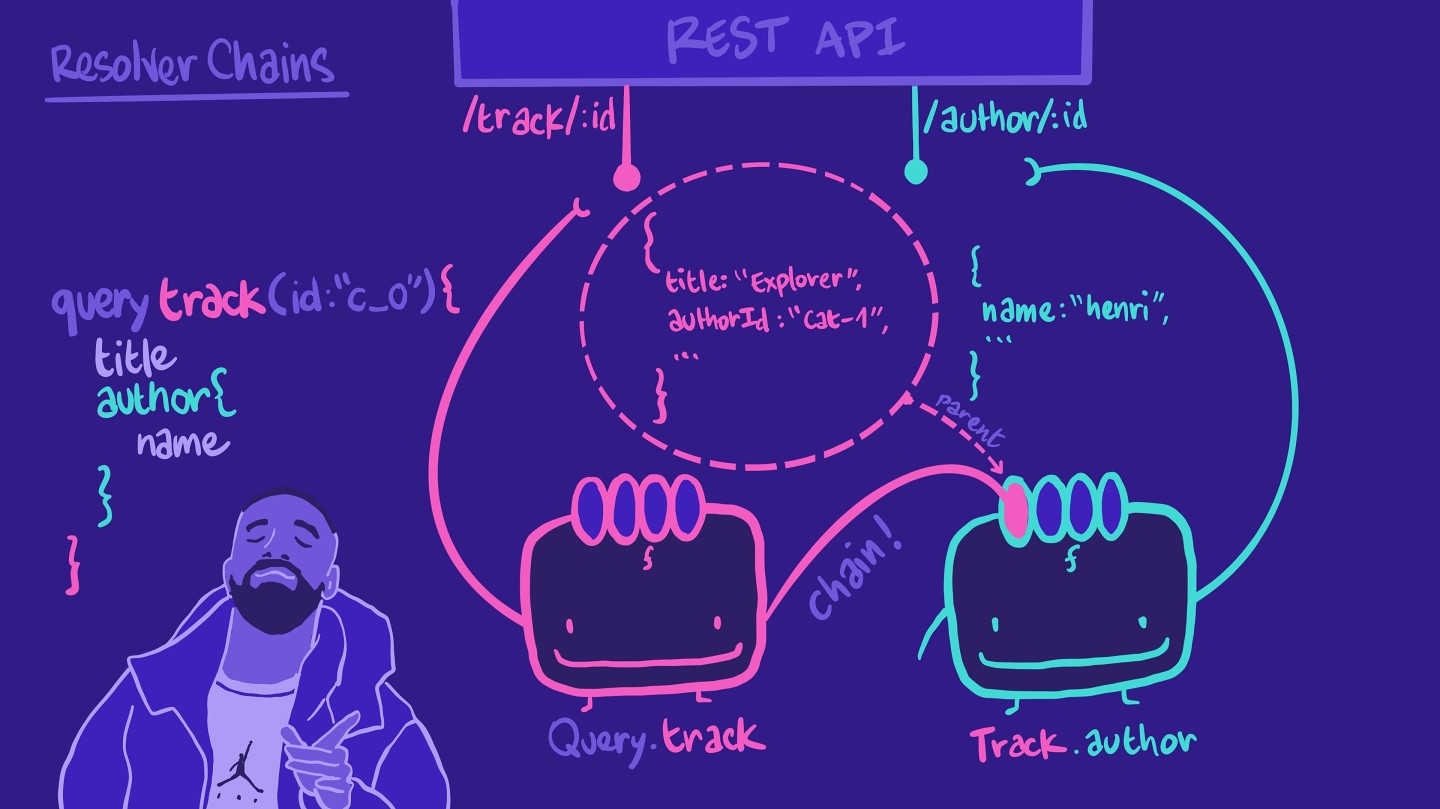
此模式使每个解析器易于阅读、易于理解,并且对未来的变更更具弹性。
args,是包含所有提供的到字段的 将此框中的项目拖到上方的空格中
变量
父元素参数
数据源
解析器链
类型
值
区域
上下文信息
✍️ 将新解剖析器添加到链中
回到我们的具体问题,让我们使用解析器链的概念来为Track.modules创建一个解析器。
我们将在这个解析器下面添加,在resolvers.js文件中
modules: ({id}, _, {dataSources}) => {return dataSources.trackAPI.getTrackModules(id);},
我们将解构第一个参数来检索父元素的id属性,那是轨道的id。我们不需要args参数,所以它可以是下划线,然后解构第三个上下文参数来获取dataSources属性。
在内部,我们可以调用我们的dataSources.trackAPI.getTrackModules方法,并传递轨道的id。
这就是我们的解析器的全部。有了这个,我们已经更新了解析器、数据源和架构,并准备好接受我们的新查询。
分享您对本课程问题的疑问和评论
您的反馈帮助我们改进!如果您遇到难题或困惑,请告诉我们,我们将帮助您。所有评论均为公开,必须遵守 Apollo准则。请注意,已经解决或响应的评论可能会被删除。
您需要GitHub账户才能在此处发布。您还没有吗? 请转而在我们的Odyssey论坛上发布。