GraphQL 查询获取数据的方式
我们已设计模式 并配置了我们的 数据源,但我们的服务器不知道如何 使用其 数据源 来填充模式 字段。要解决此问题,我们将定义一组 解析器
解析器是一个函数,它负责填充架构中单个字段的数据。每当客户端查询某个特定 字段时,解析器为该字段从适当 数据源中获取所请求的数据。
一个 解析器函数返回以下某一项:
- 解析器对应架构 字段(字符串、整数、对象等)所需的类型的数据
- 用所需类型的数据兑现承诺
解析器函数签名
在开始编写 解析器之前,我们先来看看解析器函数的签名是什么样的。解析器函数可以选择接受四个位置 参数:
fieldName: (parent, args, context, info) => data;
| 参数 | 说明 |
|---|---|
父级 | 这是该字段的父级(该父级字段的解析器总是早于该字段子项的解析器执行)解析器的返回值。 |
参数 | 此对象包含为此字段提供的全部GraphQL 参数。 |
上下文 | 此对象在为特定操作执行的所有解析器中共享。使用此对象可共享基于操作的状态,例如身份验证信息和对数据源的访问。 |
信息 | 其中包含有关操作的执行状态的信息(仅在高级情况下使用)。 |
在这 4 个参数中,我们定义的解析器主要会使用context。它使我们的解析器能够共享我们的LaunchAPI 和 UserAPI 数据源的实例。要想了解它的工作原理,我们开始创建一些解析器。
定义顶级解析器
如上所述,父字段的解析器始终在该字段子级的解析器之前执行。因此,首先为一些顶级字段(即Query类型)的字段定义解析器。
正如src/schema.js所示,我们的架构Query类型定义了三个字段:launches、launch和me。要为这些字段定义解析器,请打开server/src/resolvers.js并粘贴以下代码:
module.exports = {Query: {launches: (_, __, { dataSources }) =>dataSources.launchAPI.getAllLaunches(),launch: (_, { id }, { dataSources }) =>dataSources.launchAPI.getLaunchById({ launchId: id }),me: (_, __, { dataSources }) => dataSources.userAPI.findOrCreateUser(),},};
如下代码所示,我们定义了解决器解析器,使用映射,将映射的键与模式的类型(Query)和字段(launches、launch、me)相对应。
关于上述函数参数:
所有三个解析器函数将第一个位置参数(
parent)分配给变量_,作为惯例表示它们不使用其值。The
launches和me函数将其第二个位置参数(args)分配给__,原因相同。- (
launch函数确实使用args参数,但是,原因在于我们模式的launch字段使用id参数。)
- (
所有三个解析器函数会使用第三个位置参数(
context)。具体来说,它们会对其解构,以访问我们定义的dataSources。没有哪个解析器函数包含第四个位置参数(
info),因为它们不使用它,也没有其他需要包含它的原因。
如您所见,这些解析器函数很短!这是因为它们所依赖的大部分逻辑是LaunchAPI和UserAPI 数据源的一部分。通过将解析器保持精简作为最佳做法,您可以在安全地重构您的后端逻辑的同时,降低破坏 API 的可能性。
向 Apollo Server 添加解析器
现在我们有了一些解析器,让我们将它们添加到我们的服务器中。将高亮行添加到src/index.js中:
const { ApolloServer } = require("apollo-server");const typeDefs = require("./schema");const { createStore } = require("./utils");const resolvers = require("./resolvers");const LaunchAPI = require("./datasources/launch");const UserAPI = require("./datasources/user");const store = createStore();const server = new ApolloServer({typeDefs,resolvers,dataSources: () => ({launchAPI: new LaunchAPI(),userAPI: new UserAPI({ store }),}),});server.listen().then(() => {console.log(`Server is running!Listening on port 4000Explore at https://studio.apollographql.com/sandbox`);});
通过向Apollo Server提供您的解析器映射,它便知道如何按需调用解析器函数以履行传入的查询。
运行测试查询
让我们在我们的服务器上运行一个测试查询!使用npm start启动它并返回Apollo Sandbox(我们之前用它来探索我们的模式)。
粘贴以下查询进入操作面板:
# We'll cover more about the structure of a query later in the tutorial.query GetLaunches {launches {idmission {name}}}
然后,单击运行按钮。服务器的响应显示在右侧。请参阅响应对象如何匹配查询的结构?这种对应GraphQL的基本特征。
现在让我们尝试查询获取GraphQL 参数。粘贴以下查询并运行它:
query GetLaunchById {launch(id: "60") {idrocket {idtype}}}
这个查询返回详细信息Launch对象具有;id 60。
而不是硬编码参数如查询上面,这些工具允许您定义变量对于您操作。以下查询使用变量替代60:
query GetLaunchById($id: ID!) {launch(id: $id) {idrocket {idtype}}}
现在,粘贴以下内容到该工具变量面板:
{"id": "60"}
在继续之前,请随时尝试更多运行查询和设置变量。
定义其他解析器
您可能已经注意到上面运行的测试查询中包含了一些 fields,而我们甚至还没有编写 resolvers。但是,这些查询仍然成功运行!那是因为 Apollo Server为您未定义自定义 default resolver的任何 field定义一个
一个默认的 resolver函数使用以下逻辑:
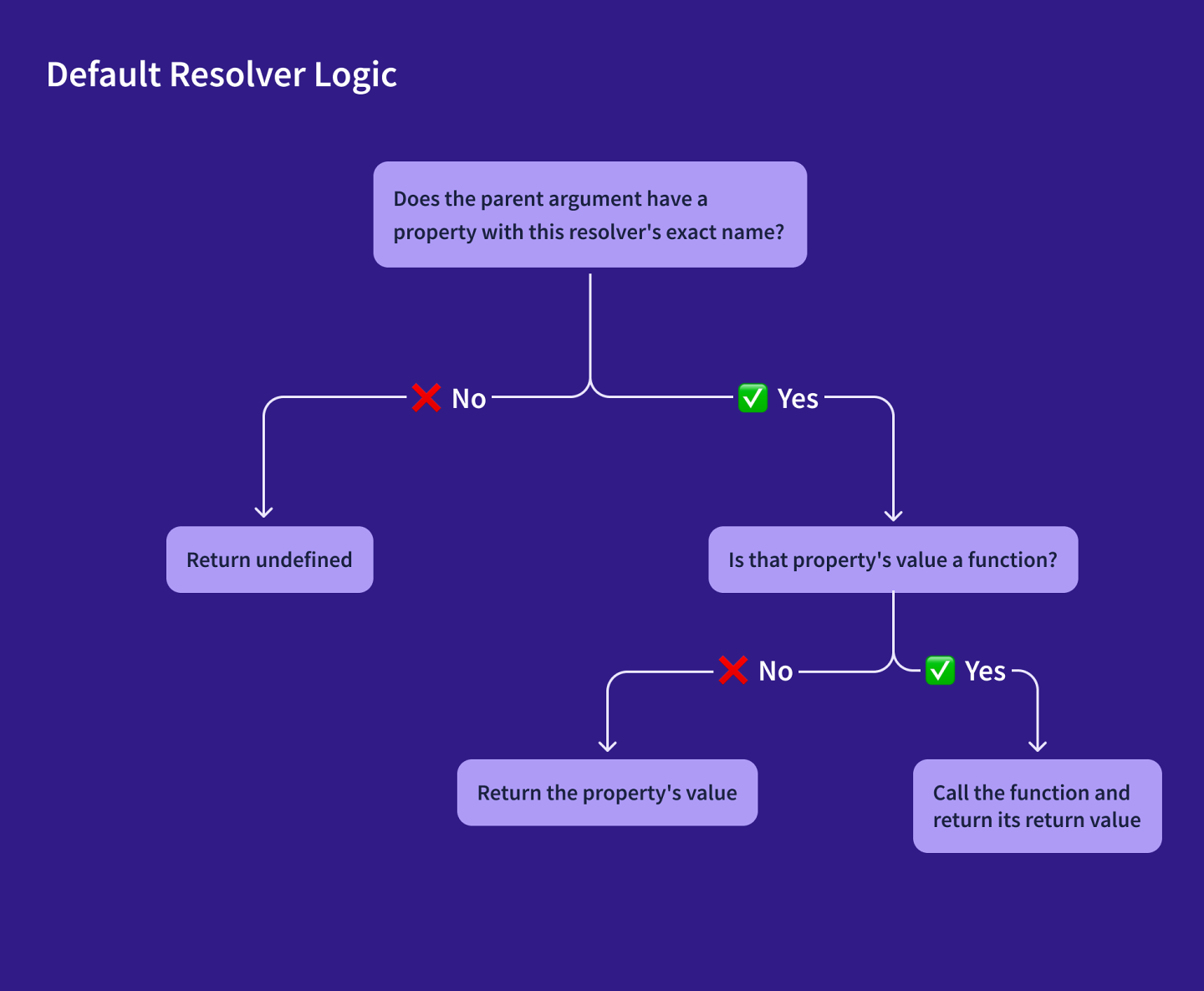
对于我们架构的大多数(但不是全部) fields,默认 resolver执行的正是我们希望它执行的操作。让我们为需要它的架构 field定义一个自定义 resolver,Mission.missionPatch。
此 field的定义如下:
type Mission {# Other field definitions...missionPatch(size: PatchSize): String}
为 Mission.missionPatch编写的 resolver应该根据 query为 size argument指定 LARGE或 SMALL返回不同的值。
在 resolver中添加以下内容,将其映射到 src/resolvers.js,置于 Query属性下方:
// Query: {// ...// },Mission: {// The default size is 'LARGE' if not providedmissionPatch: (mission, { size } = { size: 'LARGE' }) => {return size === 'SMALL'? mission.missionPatchSmall: mission.missionPatchLarge;},},
此 解析器从 mission(由默认的 解析器返回的用于我们架构中 父 字段的Launch.mission)中获取大或小补丁。
现在,我们已经了解如何为 Query之外的类型添加 解析器,让我们为 Launch和 User类型的 字段添加一些 解析器。将以下内容添加到 解析器映射(见 Mission之后):
// Mission: {// ...// },Launch: {isBooked: async (launch, _, { dataSources }) =>dataSources.userAPI.isBookedOnLaunch({ launchId: launch.id }),},User: {trips: async (_, __, { dataSources }) => {// get ids of launches by userconst launchIds = await dataSources.userAPI.getLaunchIdsByUser();if (!launchIds.length) return [];// look up those launches by their idsreturn (dataSources.launchAPI.getLaunchesByIds({launchIds,}) || []);},},
您可能会疑惑,在调用类似 getLaunchIdsByUser这样的函数时,服务器如何知道当前用户的身份。当前还不知道!我们将在下一章中解决这个问题。
分页结果
当前,Query.launches会返回一个长长的 Launch对象列表。这通常比客户端一次需要的信息更多,抓取这么多数据会很慢。我们可以通过实施 分页来提升此 字段的性能。
分页可确保我们的服务器分小块发送数据。对于编号的页面,我们推荐 基于游标的分页,因为它消除了跳过项目或重复显示同一项目的可能性。在 cursor-based pagination 中,使用一个常量指针(或游标)来跟踪从数据集中何处开始获取下一组结果。
让我们设置光标分页。在src/schema.js,更新Query.launches以匹配以下内容,并添加一个名为LaunchConnection的新类型,如下所示:
type Query {launches( # replace the current launches query with this one."""The number of results to show. Must be >= 1. Default = 20"""pageSize: Int"""If you add a cursor here, it will only return results _after_ this cursor"""after: String): LaunchConnection!launch(id: ID!): Launchme: User}"""Simple wrapper around our list of launches that contains a cursor to thelast item in the list. Pass this cursor to the launches query to fetch resultsafter these."""type LaunchConnection { # add this below the Query type as an additional type.cursor: String!hasMore: Boolean!launches: [Launch]!}
现在,Query.launches接受两个参数(pageSize和after)并返回一个LaunchConnection对象。LaunchConnection包括:
launches的列表(查询请求的实际数据)- 一个
cursor表示数据集中当前位置 - 一个
hasMore布尔值表示数据集是否包含launches中包含的内容之外的任何其他项目
打开src/utils.js并签出paginateResults函数。这是来自服务器分页数据的帮助器函数。
现在,让我们更新必要的解析器函数以适应分页。导入paginateResults并替换launches 解析器函数src/resolvers.js中的以下代码:
const { paginateResults } = require("./utils");module.exports = {Query: {launches: async (_, { pageSize = 20, after }, { dataSources }) => {const allLaunches = await dataSources.launchAPI.getAllLaunches();// we want these in reverse chronological orderallLaunches.reverse();const launches = paginateResults({after,pageSize,results: allLaunches,});return {launches,cursor: launches.length ? launches[launches.length - 1].cursor : null,// if the cursor at the end of the paginated results is the same as the// last item in _all_ results, then there are no more results after thishasMore: launches.length? launches[launches.length - 1].cursor !==allLaunches[allLaunches.length - 1].cursor: false,};},},};
让我们测试光标我们刚刚实现的分页。使用npm start重新启动服务器,并在Apollo Sandbox中运行以下查询:
query GetLaunches {launches(pageSize: 3) {launches {idmission {name}}}}
得益于我们的分页实现,服务器现在应该仅返回三个启动而不是完整列表。
这样就处理好了我们架构查询的 解析器!接下来,我们来为架构的 突变 编写解析器。