为什么采用GraphQL?
GraphQL和Apollo帮助您更快地交付功能
在现代应用程序中管理数据具有挑战性。大多数应用程序需要
- 针对多个平台(网页、iOS等)的不同前端客户端,每个客户端都有不同的数据需求
- 后端从多个来源(Postgres、Redis等)为客户端提供数据
- 前端和后端的复杂状态和缓存管理
通过采用GraphQL 和 Apollo,您可以将这些挑战大大降低。GraphQL的声明性模型帮助您创建一个一致、可预测的API,您可以使用它来满足所有客户端的需求。随着您添加、删除和迁移后端数据存储,该API在客户端视角上不会发生变化。
即便具有许多其他优势, GraphQL 的最大好处是它为开发者提供的体验。向API中添加新的类型和 字段 非常简单,客户端开始使用这些字段也同样简单。这有助于您快速设计、开发和部署功能。
结合Apollo开源库,复杂的考虑因素,如缓存、数据 规范化 和乐观的UI渲染,也变得简单直接。
GraphQL提供声明性、高效的数据获取
GraphQL在数据获取方面的声明性方法,与REST API相比提供了显著的性能和用户体验提升。
考虑一个显示本地动物避难所可供领养的可爱宠物的网页。 🐶
使用REST
使用REST,页面可能需要
GET从/api/shelters端点获取庇护所及其对应的pet_id列表GET通过向/api/pets/PET_ID发送单独的请求来获取每只宠物详情(名称、照片URL等)。
这种方案需要多次依赖的网络请求,可能会导致页面加载速度变慢,并在移动设备上增加额外的电池消耗。这种逻辑也难以在其他显示略微不同数据的页面上重用。
使用GraphQL
使用 GraphQL,页面可以通过向单个端点发送单个查询来获取所有这些数据。查询如下所示:
query GetPetsByShelter {shelters {namepets {namephotoURL}}}
此 查询描述了我们需要从GraphQL服务器获取的数据形状。服务器负责组合和过滤后端数据,返回我们请求的确切数据。这保持了数据负载的大小,特别是与可能返回数百个不必要字段的大型REST端点相比。
要执行与上方类似的查询,页面使用 GraphQL客户端,例如 Apollo客户端,代码类似于以下(以React应用程序为例):
// Define the queryconst GET_PETS_BY_SHELTER = gql`query GetPetsByShelter {shelters {namepets {namephotoURL}}}`;function MainPage() {// Execute the query within the component that uses its resultconst { loading, error, data } = useQuery(GET_PETS_BY_SHELTER);if (error) return <Error />;if (loading || !data) return <Fetching />;// Populate the component using the query's resultreturn <PetList shelters={data.shelters} />;}
Apollo Client's useQuery 插件自动处理请求的生命周期,从开始到结束,包括跟踪加载和错误状态。你无需配置中间件或编写样板代码即可发送第一个请求。你只需描述组件所需的数据,让Apollo Client 坦负重活。 💪
GraphQL 提供了强大的工具
多亏了GraphQL 的严格类型定义 和内建的审查 ,GraphQL 的开发者工具非常强大。这些工具让你可以执行以下操作:
- 探索结构化模式的完整结构,包括文档字符串。
- 使用实时验证和自动完成来编写新的操作。
- 将您的模式注册到跟踪并检查变更的管理服务
什么是 Apollo GraphOS?
Apollo 为构建您的图,衡量其性能,并安全地扩展它提供了一组云托管的工具。这些工具统称为Apollo GraphOS。
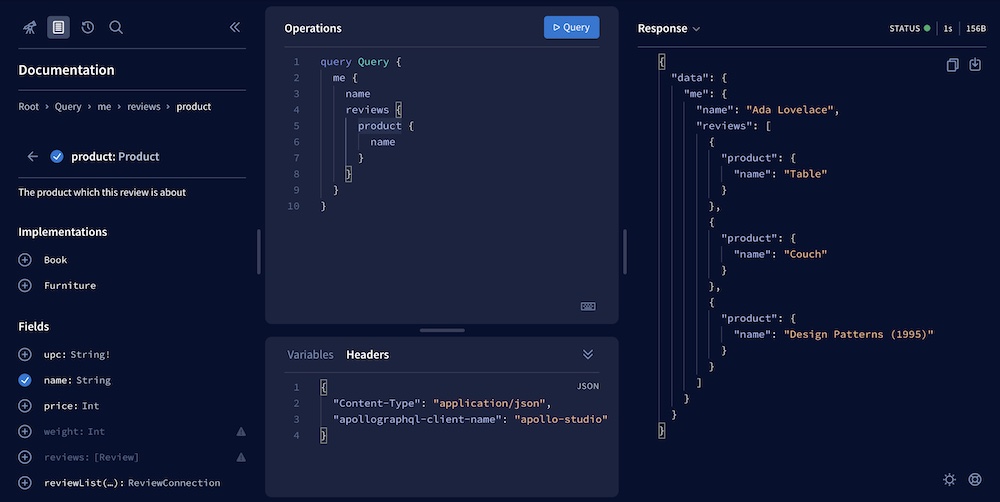
在将模式注册到GraphOS 后,您可以使用GraphOS Studio Explorer 来检查所有类型和字段。
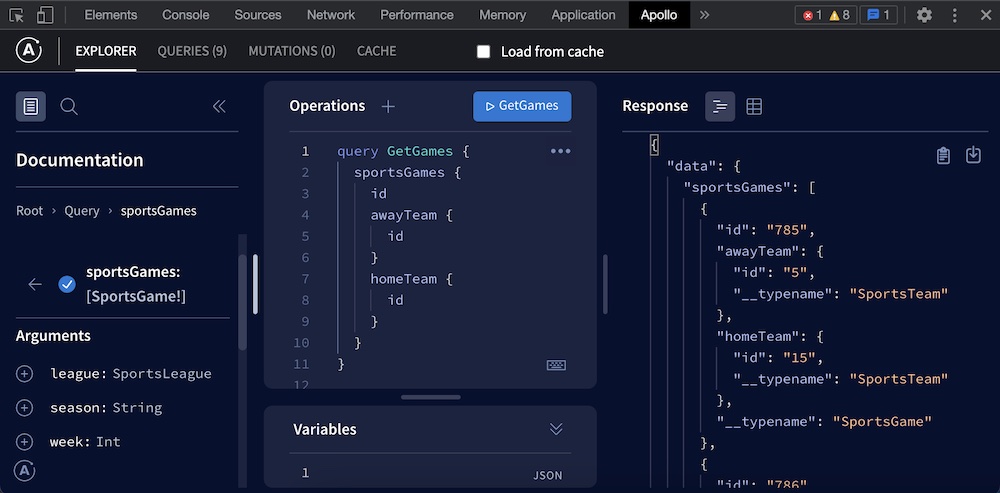
Apollo 客户端 DevTools
Apollo Client 开发者工具扩展为 Chrome 和 Firefox 提供了使用全局配置,跟踪活动查询以及查看 突变。它还包含一个内嵌的浏览器,在您处理前端代码时,可以帮助您测试查询。
GraphQL 已获生产支持
自从 Facebook 在 2015 年发布原始 规范 以来,GraphQL 的采用率稳步上升。对于越来越多的组织,GraphQL 的好处使其从好奇工程师的Hack-week实验转变为企业数据层核心。
GraphQL 可以适应甚至最大组织的要求,这主要归功于其 强大的工具 和 联邦架构 兼容性。
在联邦架构,也称为 超图,单个 GraphQL 模式 被分割到多个后端服务中。组织中的每个团队都可以拥有他们应该拥有的服务(以及相应的模式部分)。
使用 GraphQL 的组织
以下是几家在生产环境中采用 GraphQL 并从中受益的组织的一些博客文章:
GraphQL 交易的权衡
在决定是否采用一项技术时,理解技术的局限性同样重要,就像理解其好处一样。
在使用 GraphQL 时,请考虑以下权衡:
变更管理
GraphQL 引入了一种新的数据表示和交互的概念模型。对这种模型感到舒适的组织可以快速设计、实施和发布功能。然而,适应这种模型的过程需要时间。
- 前端开发者必须熟悉新的 API 以获取和操作数据。
- 后端开发者必须熟悉如何处理来自前端的活动请求。
- 组织内的开发者必须协作设计单一的产品驱动的 GraphQL 模式,并指定人员作为该模式的官方维护者。
Apollo 文档、博客以及社区论坛都可供您的组织采用 GraphQL 并充分利用它。
操作可能缓慢
您的 GraphQL 模式定义了客户端可以查询哪些类型和字段。您的 GraphQL's 解析器定义了这些类型和字段是如何从您的数据存储中填充的。
根据您的模式和解析器定义,您的服务器可能会无意中支持执行缓慢的 GraphQL 操作,甚至耗尽服务器资源。
因此,设计您的模式以支持客户端所需的操作,而不支持影响性能的不必要操作非常重要。设置 跟踪报告对于您的 GraphQL 服务器也很有帮助,这样您就可以识别并改进慢速操作。
与 Web 浏览器缓存的兼容性问题
尽管 Apollo Client 提供了强大的客户端缓存功能,但通常需要一些配置才能充分发挥其功效。您的 Web 浏览器提供的自动缓存与 GraphQL 的交互不佳。
Web 浏览器根据 URL 缓存获取的数据。在 GraphQL 中,您从相同的 URL(您的 GraphQL 服务器)获取所有数据。因此,您不能依赖此 URL 的缓存值。