👋 欢迎来到我们发射系列的第二部分!
在发射 I 中,我们为 Catstronauts 应用程序构建了首页网格功能,这是一个面向想要探索宇宙的猫的学习平台。我们使用先 schema 的方法设计了该功能并模拟了静态数据。我们多次显示一个模拟条目来填充首页网格的卡片。
现在是时候将这个应用程序连接到真实数据了!
在本课程结束后,您的 Catstronauts 首页将如下所示
点火序列...
先决条件
我们的应用程序在后端使用 Node.js,在前端使用 React。我们建议使用最新版本的 Node.
在本课程中,我们将只关注后端。
克隆仓库
注意:本课程提供 JavaScript 和 TypeScript 版本。在继续之前,请确认您在课程顶部选择了您的首选语言。
在您选择的目录中,使用您喜欢的终端,克隆应用程序的启动仓库
git clone https://github.com/apollographql/odyssey-lift-off-part2
项目结构
此仓库接续发射 I 的内容。我们的项目是一个全栈应用程序,后端应用程序位于server/目录中,前端应用程序位于 client/目录中。
您还会找到一个 final/文件夹,其中包含您完成课程后项目的最终状态。您可以将其用作参考!
以下是文件结构
📦 odyssey-lift-off-part2┣ 📂 client┃ ┣ 📂 public┃ ┣ 📂 src┃ ┣ 📄 index.html┃ ┣ 📄 package.json┃ ┣ 📄 README.md┃ ┣ 📄 vite.config.js┣ 📂 server┃ ┣ 📂 src┃ ┃ ┣ 📄 index.js┃ ┃ ┣ 📄 schema.js┃ ┣ 📄 README.md┃ ┣ 📄 package.json┣ 📂 final┃ ┣ 📂 client┃ ┣ 📂 server┗ 📄 README.md
现在,在您喜欢的 IDE 中打开仓库。
让我们从服务器应用程序开始。
在终端窗口中,导航到仓库的 server目录并运行以下命令来安装依赖项并运行应用程序:
npm install && npm start
注意:我们建议使用最新版本的 LTS Node。要检查您的 Node 版本,请运行 node -v.
如果一切顺利,您将看到安装完成以及一条消息,指示服务器正在运行。
接下来,是客户端应用程序。
在新的终端窗口中,导航到仓库的 client目录并运行以下命令来安装依赖项并启动应用程序:
npm install && npm start
控制台中应该显示一些输出,以及指向位于 localhost:3000 的运行应用程序的链接。您可以在浏览器中导航到 https://:3000,您将看到我们的首页,其中显示了一个 Track 卡,重复了几次。这是我们在第一部分设置的模拟数据。
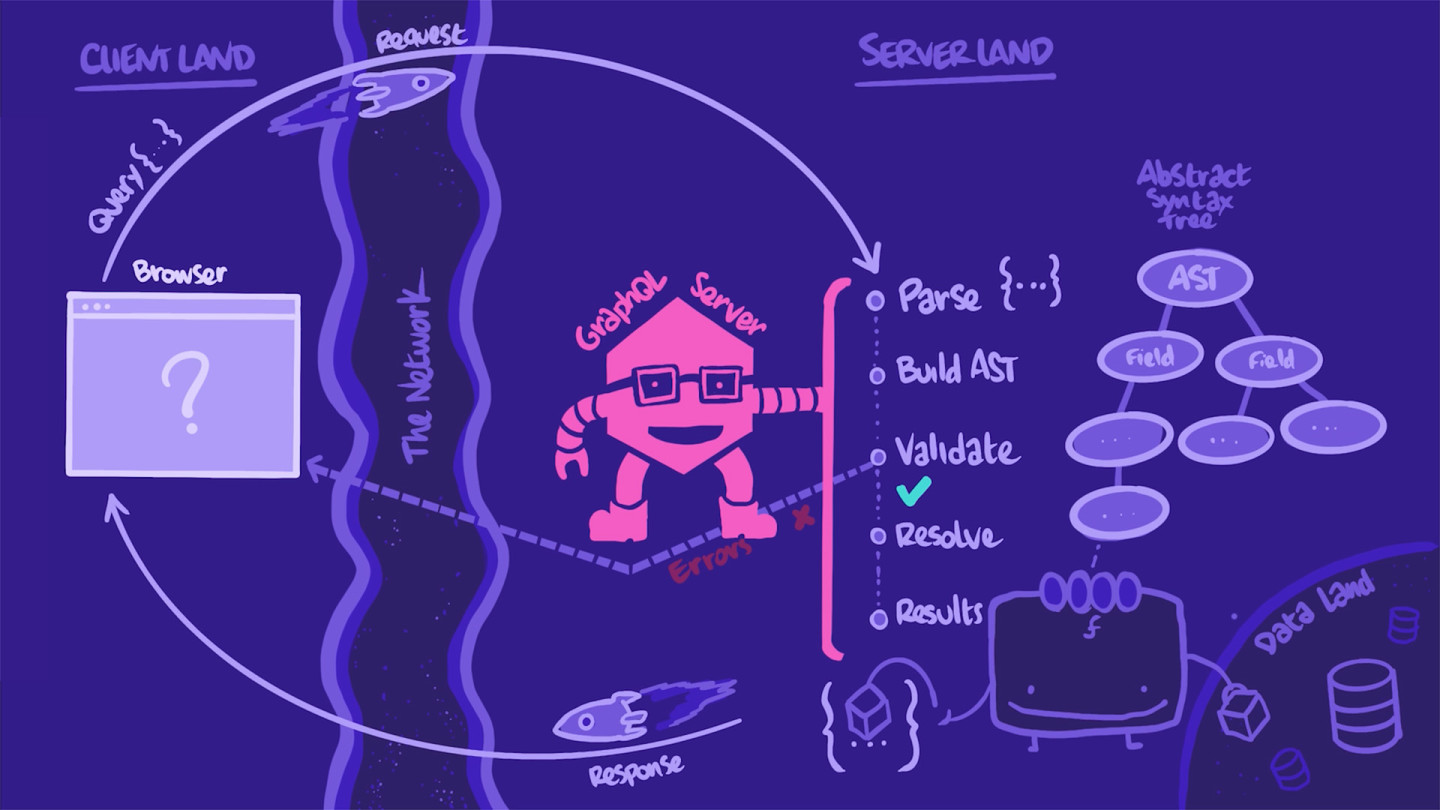
要了解我们的 GraphQL 服务器 缺少什么才能使用实时数据,以及它将如何知道从哪里获取什么,让我们退一步并探索 GraphQL 查询之旅.
GraphQL 查询之旅

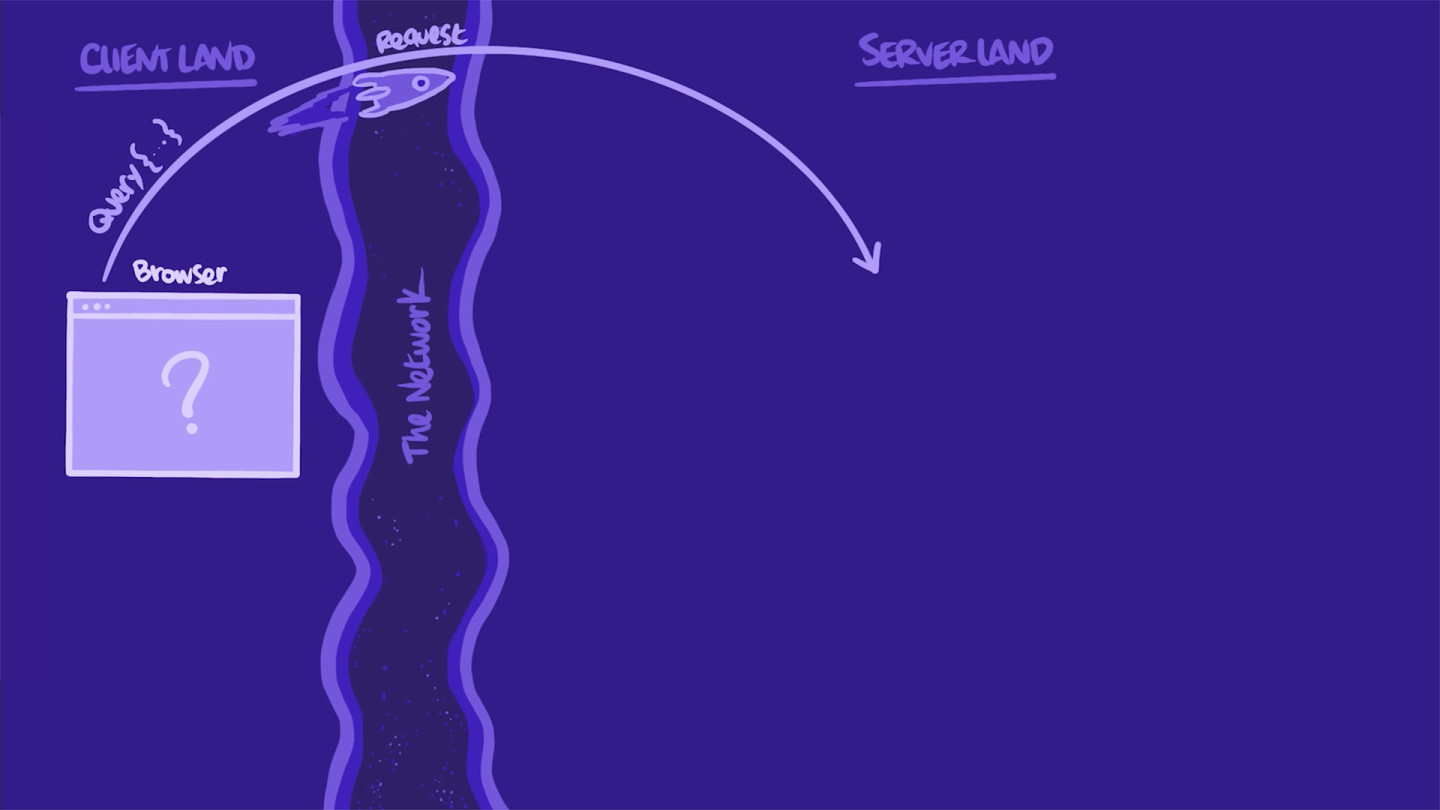
在客户端中
我们的 Web 应用程序需要获取远程数据来填充其首页。
要获取该数据,它会向我们的 GraphQL 服务器 发送一个 查询。应用程序将查询塑造成一个字符串,该字符串定义它所需的 选择集 的 字段。然后,它将该查询作为 HTTP POST 或 GET 请求发送到服务器。
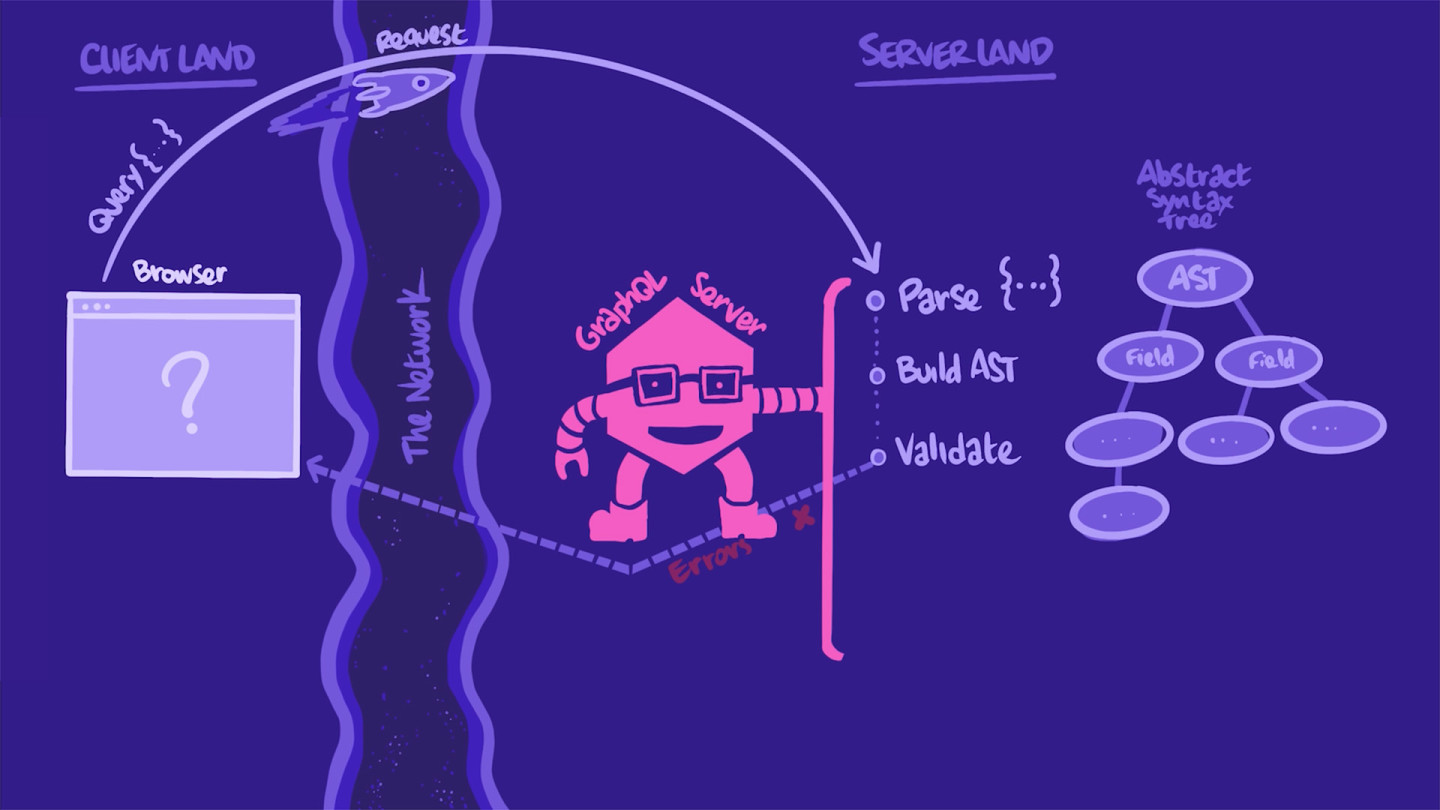
在服务器中
当我们的服务器接收到 HTTP 请求时,它首先提取包含 GraphQL 查询 的字符串。它会解析并将其转换为更容易操作的形式:一种称为 文档 的树状结构,称为 AST (抽象语法树)。使用此 AST,服务器会根据我们 schema 中的类型和 字段 来验证 查询。
如果出现任何错误(例如,请求的 字段 未在 schema 中定义,或者 查询 格式错误),服务器将抛出错误并将其直接发送回应用程序。
在这种情况下,查询 看起来不错,服务器可以“执行”它。这意味着服务器可以继续其流程并实际获取数据。服务器会沿着 AST 遍历。
对于 查询 中的每个 字段,服务器都会调用该字段的 解析器 函数。解析器函数的任务是通过从数据库或 REST API 等正确来源填充正确的数据来“解析”其字段。
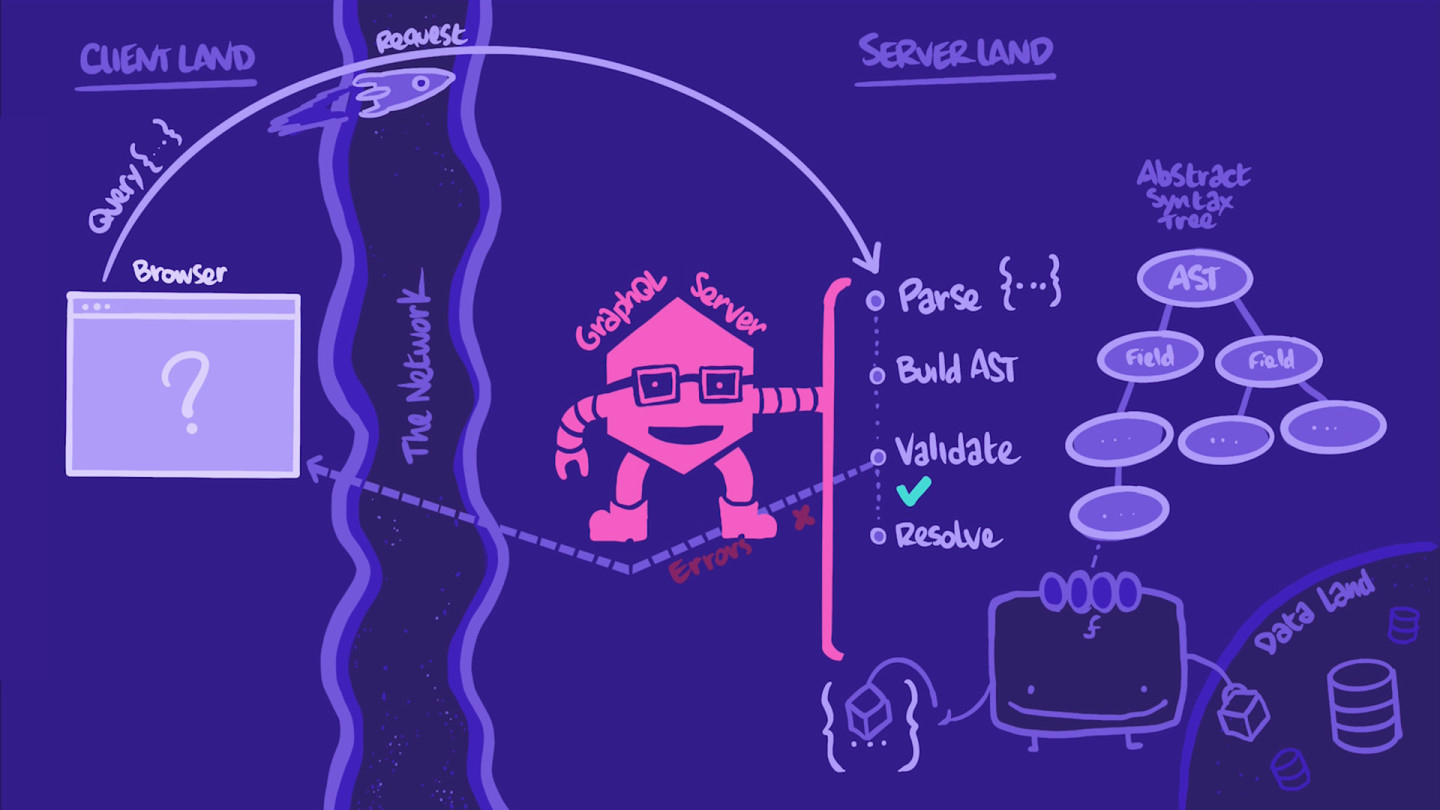
当所有 查询 的 字段 都解析后,数据将被组装成一个按相同顺序排列的 JSON 对象,其形状与查询完全相同。
服务器将该对象分配给 HTTP 响应主体中的 data 键,现在是返回应用程序的时候了。
返回客户端
我们的客户端接收包含所需数据的响应,将这些数据传递给正确的组件以进行渲染,然后,我们的首页会从远程数据中显示其卡片。
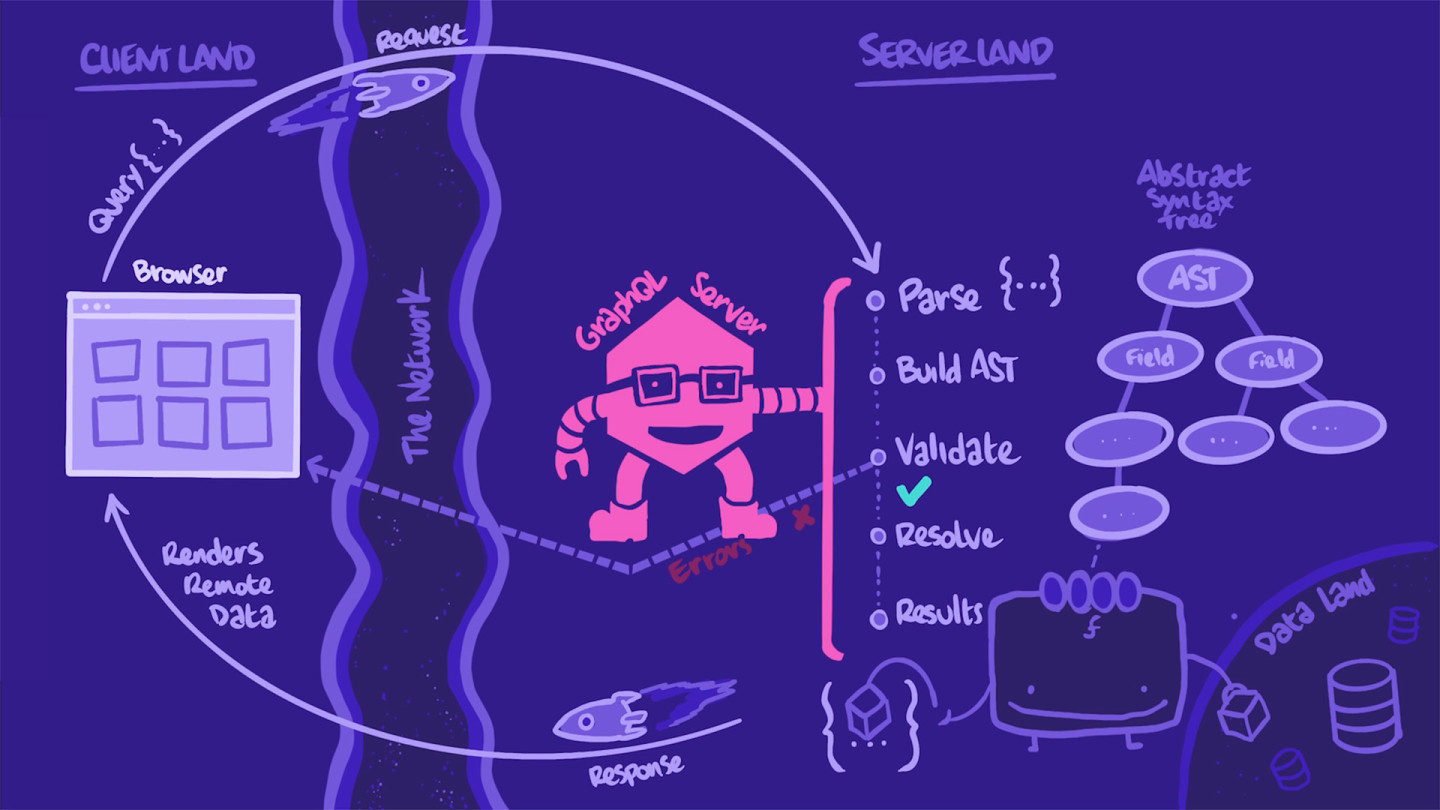
这便是 GraphQL 查询 的旅程!
分享您对本课程的疑问和评论
您的反馈有助于我们改进!如果您遇到问题或困惑,请告知我们,我们将帮助您。所有评论都是公开的,必须遵循 Apollo 行为准则。请注意,已解决或处理的评论可能会被删除。
您需要一个 GitHub 帐户才能在下面发布。没有帐户吗? 请在我们的 Odyssey 论坛中发布。