概述
在本课中,我们将
- 探讨“Schema 优先”设计
- 了解以下内容的基础知识模式定义语言 (SDL)
定义数据
在动手之前,我们需要回答一个重要问题:我们需要哪些数据来构建此功能?
让我们看看设计团队为我们绘制的模型。以下是主页应具有的样子:一个整洁的卡片网格。
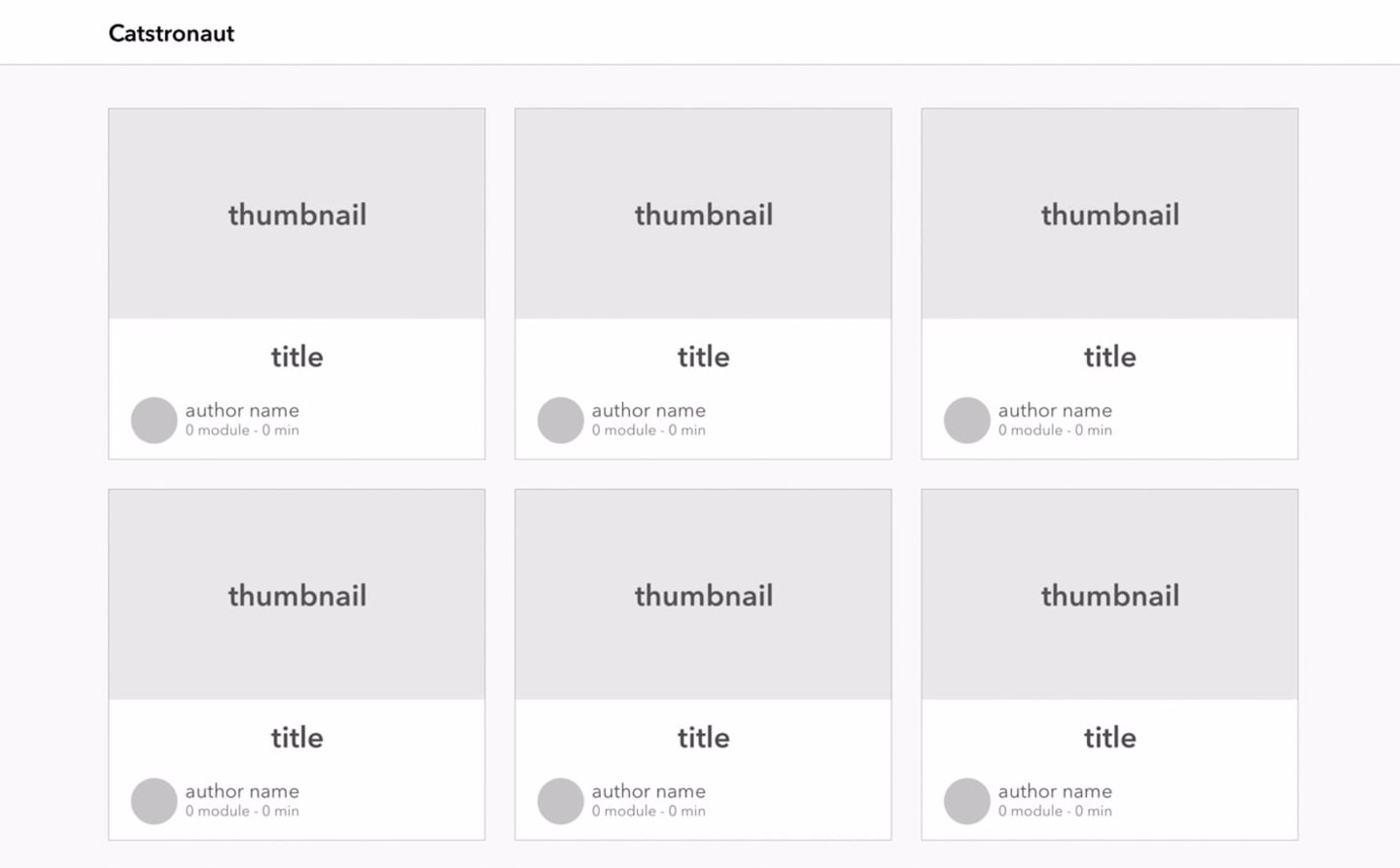
在继续之前,请花点时间查看模型并确定哪些信息可能需要来填充单个卡片。
基于模型,似乎我们需要为每个学习路径提供以下信息
- 标题
- 缩略图
- 时间长度(估计持续时间)
- 模块数量
- 作者姓名
- 作者图片
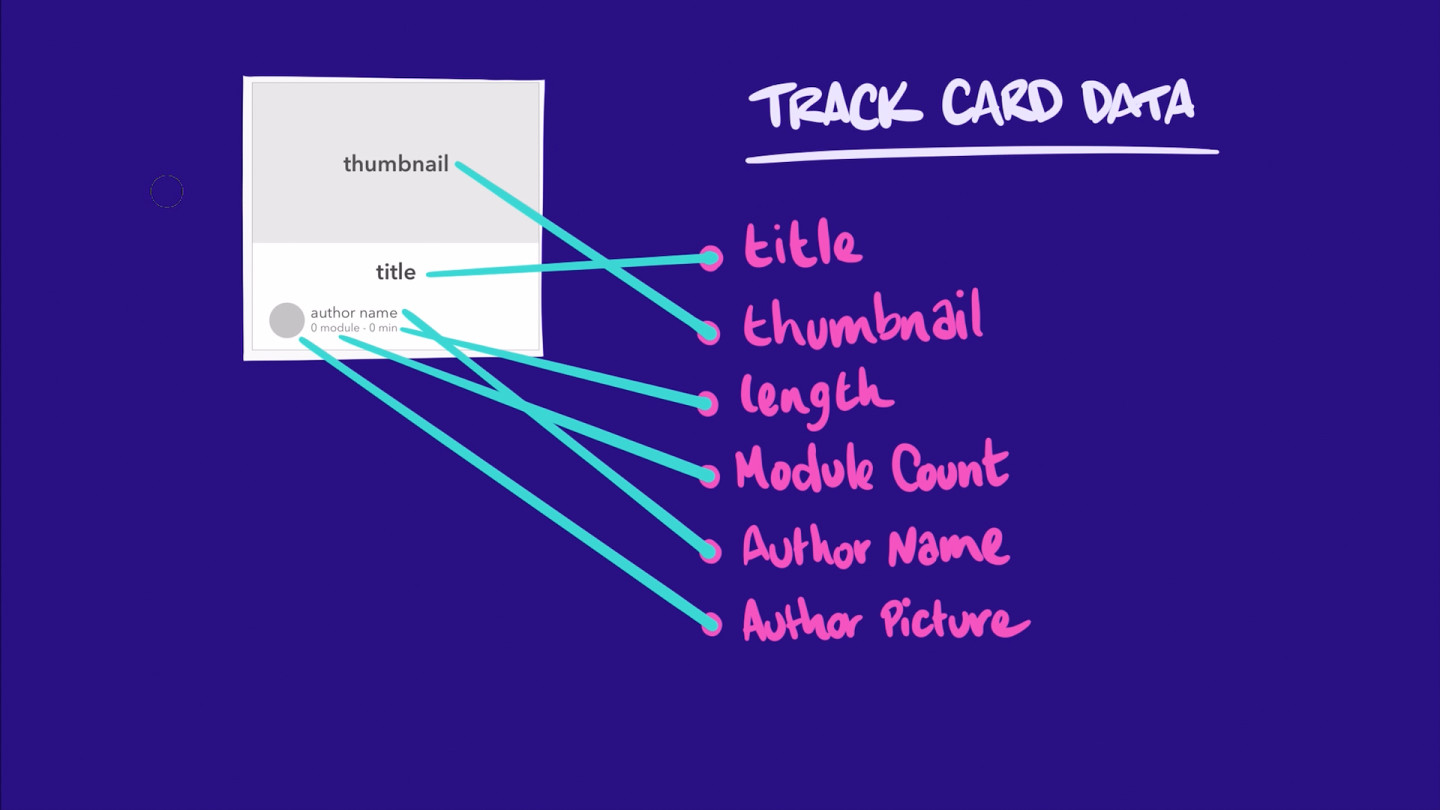
图表
查看以上列表,我们可以开始将我们应用程序的数据视为 对象集合(例如学习路径和作者)以及对象之间的 关系(例如每个学习路径都有一位作者)。
现在,如果我们将每个对象看做一个 节点,将每段关系视为两个节点之间的 边,那么我们可以将整个数据模型看做一个 图,其中包括节点和边。这就是我们应用程序的 图。
以下是我们应用程序的 图的不完整表示,它完全基于我们模型的数据需求:
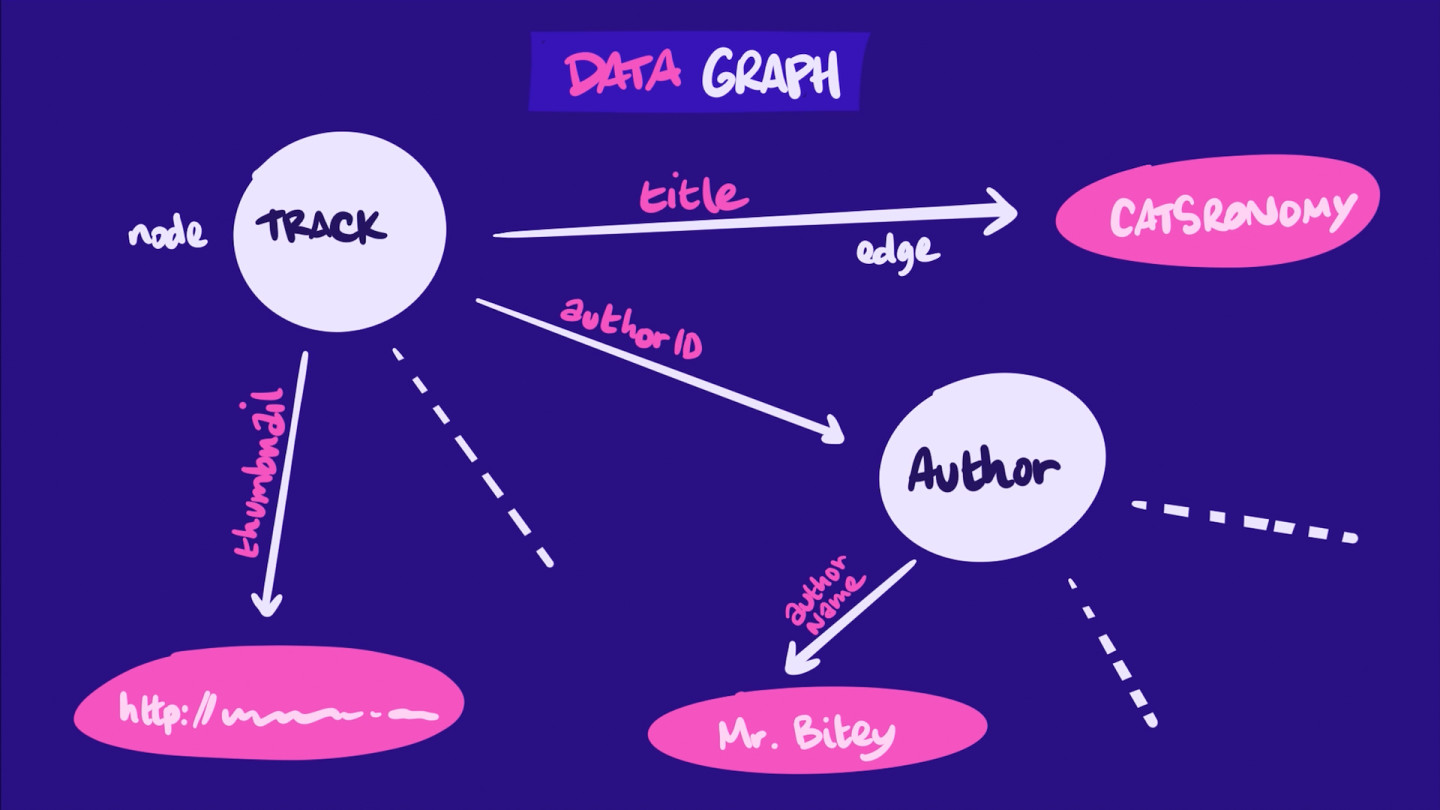
该 图 结构反映了我们期望在 GraphQL 架构(文档)中发现的关系类型,该 文档 详细说明了我们应用程序数据能力的类型、字段 和关系!
通过在开始时定义我们前端所需的数据类型,我们采用了一种策略,称为 模式优先设计。
模式优先设计
还记得我们在上一课中提到的模式吗?(提示:它是 文档,它定义了我们所处理的数据类型,以及它们之间的关系!)
那么,“模式优先”设计是一种通用约定,后端和前端团队在使用 GraphQL 时使用它。它使我们能够根据我们的客户端应用程序所需的数据类型,精确地实现我们的 GraphQL 架构。
模式优先设计通常涉及三个主要步骤
- 定义模式:我们确定我们的功能需要哪些数据,然后我们构建我们的模式,以尽可能直观地提供该数据。前端和后端之间的协作在这里至关重要!
- 后端实施:我们在服务器端构建我们的 GraphQL API,从包含所需数据的任何 数据源 中获取并准备这些数据。
- 前端实施:我们的客户端从我们的 GraphQL API 消耗数据,以呈现其视图。
为了完成本课程,我们将标记第 1 步和第 2 步已完成——我们刚刚浏览了所需数据,并且我们可以想象我们的后端团队已经定义了模式并实现了服务器逻辑。现在,我们的工作重点是第三步:使用 GraphQL API 提取数据并呈现视图!
为此,我们需要熟悉 模式定义语言(或 SDL)。
如果您已熟悉 SDL,请随时进入下一课。
模式定义语言 (SDL)
我们的模式充当服务器和客户端之间的 契约,定义 GraphQL API 可以或不可以执行哪些操作,以及客户端如何请求或更改数据。这是一个抽象层,为使用者提供灵活性,同时隐藏后端实现细节。
我们使用 模式定义语言(SDL)来定义构成模式的 对象类型和 字段。
类型和字段
GraphQL类型以 type关键字开头,后接类型名称(帕斯卡命名法是一种最佳实践),然后用花括号括起包含的 字段:
type Track {# Fields go here}
字段通过字段名称(驼峰式)、冒号和字段的类型(标量或对象)进行声明。
type Track {title: String}
架构中的每个 字段都有自己的一个类型。字段的类型可以是 标量(例如上面所示的 Int或 String),也可以是 另一个对象类型。
type Track {title: Stringauthor: Author}
一个 字段还可以包含一个列表,列表用方括号表示:
type Track {title: String!author: Author!modules: [Module]}
与 Javascript 对象(非常相似)不同的是, 字段之间不会用逗号分隔。
此外,我们可以指示每个 字段的值是否可空或者不可空。如果一个字段永远不可为空,那么我们可以在其类型后添加一个感叹号:
type Track {title: String!author: Author!modules: [Module!]!}
描述
最好做法是记录架构,就像对代码进行注释一样。描述让使用者更容易理解 API 中发生了什么。它们还可以允许诸如GraphOS Studio Explorer之类的工具(下一课将详细介绍!)指导 API 使用者在需要时和需要的位置使用 API 完成哪些任务。
在SDL中描述可通过直接在它们上面写字符串(使用引号)应用于类型字段
"I'm a regular description"
三重“双引号”允许您添加换行符以更清晰地格式化较长的注释。
"""I'm a block descriptionwith a line break"""
下面是Track类型,已使用一些有用的描述更新!
"A track is a group of Modules that teaches about a specific topic"type Track {"The track's title"title: String!"The track's main Author"author: Author!"The track's complete array of Modules"modules: [Module!]!}
GraphQL API
我们将使用预先构建的GraphQLAPI 使我们的前端焕然一新。让我们使用Apollo Sandbox来了解此 API。Sandbox 是GraphOS Studio的一种特殊模式,允许您在整个课程中将探索的大量功能中,测试GraphQLAPI。
让我们打开浏览器到Sandbox Schema Reference 页面。在这里,我们将看到Schema概览页面,但是现在还没有太多内容可以看。看到屏幕顶部的红点了吗?这表示 Sandbox 尚未连接到任何内容。

我们先将其连接到整个课程中都将使用的GraphQLAPI。复制以下 URL,然后将其粘贴到页面顶部端点输入中。
https://odyssey-lift-off-server.herokuapp.com/
几分钟后,我们将会看到点变成绿色,即 Sandbox 已成功连接到我们的 API!我们还将注意到界面更新了一些新数据。

让我们点击 对象左菜单中的选项。这将我们带到 API 的 对象类型;它们描述此 GraphQL API 架构处理的不同对象。

为我们提供有关音轨、模块及其作者的数据,此 API 架构包含一些 对象类型我们可能预期: Track、 Module和 Author。(稍后我们会了解到那个 IncrementTrackViewsResponse类型!)

我们可以点击 Track类型来仔细查看它包含的数据类型。

此类型让我们清晰了解了音轨对象中包含的所有内容: 字段我们可以在此类型中访问,以及它们的描述和它们返回的数据类型。
我们还可以开始设想一个 对象类型如何与另一个相关联。例如,每个 Track实例都有一个 author 字段,它返回一个新的 对象类型, Author!此外,我们预期每个 Track都包含 Module类型的列表。

但架构仅有这三个 对象类型是不够的;我们还需要一种实际上 向我们的 GraphQL API 请求数据的方式。
Query类型
为我们可采用以访问我们数据的方式提供定义,我们的架构提供 查询 类型。例如,我们希望 查询歌曲的列表,而查询 类型为我们提供了一种方式来实现这一点!
让我们回到 查询 页面,通过退出沙盒视图中的 对象类型 并返回到 查询 页面。

存在于 查询 类型中的每个 字段 都可以被认为是我们数据的一个“入口点”。它定义了我们可要求的某个非常具体的事项(例如 tracksForHome)以及我们可预期从运行此 查询 接收的数据类型(一个由非空 Track 类型组成的非空列表)。

尽管我们一直保持对架构的观察基本上属于宏观层面,但你可以深入研究将此架构结合在一起的实际语法。
从 架构 页面选择顶部处的 SDL 选项。这将打开整个 GraphQL API(以其原始 SDL 存在),供你浏览!

让我们对我们了解到的有关我们的架构及其类型的知识,然后看看我们如何实际应用它们来使用一些数据!
练习
> 主要要点
- GraphQL 包含类型和字段,以Schema (SDL) 编写。
- 通过添加感叹号 (
!),可以将字段标记为非空。 - 在SDL
"单行描述"),或包含在三对双引号 ("""多行描述""") 中。 - 模式的
Query类型定义 API 的入口点,并限制可以查询的数据类型。 - 沙盒是GraphOS StudioGraphQLAPI。
后续
我们已经从模式的角度探索了 API 的类型和字段;现在是时候了解如何使用这些定义构建查询,并获取一些数据了!在下一节中,我们将开动 API 试用一下。
分享你对本课程的问题和评论
此课程目前处于
你需要一个 GitHub 帐户才能在下方发帖。还没有一个? 相反,请在我们的 Odyssey 论坛中发布。