概述
在服务器能够解析一个GraphQL 操作的数据之前,它首先需要提取和验证该操作本身。这涉及一些必须在任何数据检索之前发生的步骤。
在本节课中,我们将
- 回顾一个 操作 是如何被一个 GraphQL 服务器 收到、解析和验证的。
- 学习关于
PreparsedDocumentProvider接口 - 讨论在缓存操作时使用 查询 变量 的最佳实践
GraphQL 操作和服务器
让我们首先回顾一下当我们的服务器接收到一个 GraphQL 操作 时幕后发生了什么。
这个过程从客户端通过 HTTP POST 或 GET 请求提交一个 操作 开始。当我们的服务器接收到 HTTP 请求时,它首先提取包含 GraphQL 操作的字符串。它解析并转换成它可以更好地操作的格式:一个名为抽象语法树 (AST) 的树状结构文档。有了这个 AST,服务器将操作与模式中的类型和 AST (抽象语法树)进行验证,这里的类型和 字段 在我们的模式中。
如果有任何问题(例如,请求的 字段 在模式中未定义或操作格式不正确),服务器会抛出一个错误,并将错误立即发送回应用程序。
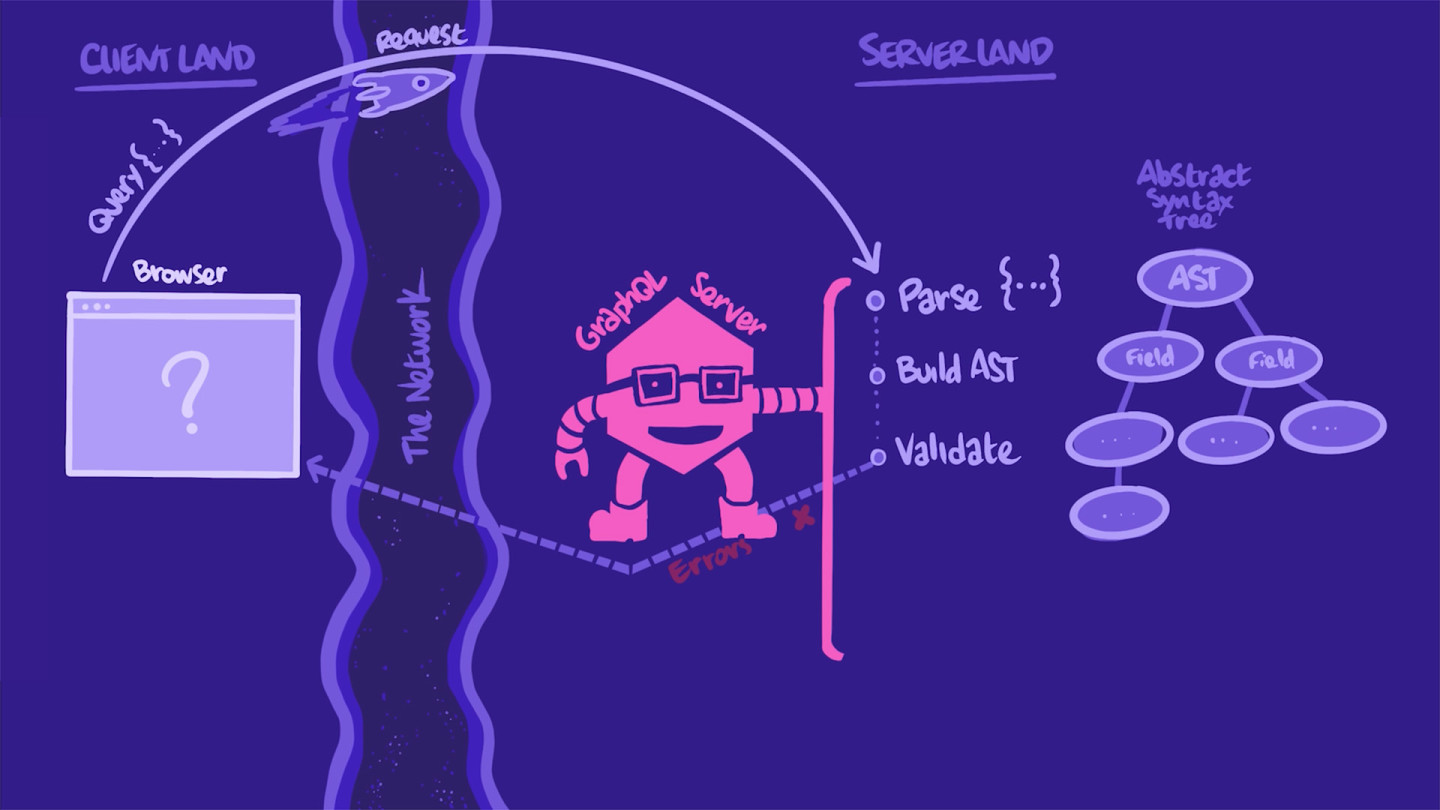
如果操作看起来良好,服务器就会继续“执行”它:对于操作中的每一个字段,服务器都会调用该字段的数据检索方法。当所有字段都解决完毕后,服务器将数据打包成一个匹配原始查询形状的单个JSON对象。然后数据就会返回给客户端!
这个过程很高效,但当服务器接收到多次相同的操作时会发生什么呢?服务器会像以前一样执行:提取操作,将其解析为抽象语法树(AST),并对结果进行模式验证。只有在完成这些步骤后,服务器才会继续调用每一个字段的数据检索方法。这意味着即使服务器之前已经解析和验证过一次或两次特定的操作,它仍会为每个新的请求重复这些步骤。
我们可以通过操作缓存来改进这个过程。
缓存操作字符串
当我们为我们的服务器配置缓存接收到的操作字符串时,我们可以避免在服务器处理过程中重复两个可能昂贵的步骤:解析和验证请求字符串。通过为我们的GraphQL操作创建一个特定的缓存,服务器可以解析和验证唯一的操作一次,然后在将来收到相同的操作时,引用缓存的文档。
为了将此功能引入我们的DGS服务器,我们将使用GraphQL Java库的PreparsedDocumentProvider接口。在我们深入实际实现之前,先让我们来了解这个接口是如何工作的。
PreparsedDocumentProvider 接口
该PreparsedDocumentProvider接口通过存储在我们在该接口中提供的缓存实例中GraphQL操作(在接口中称为Document)来工作。
每当我们的服务器收到一个传入的 操作字符串时,PreparsedDocumentProvider的实现会使用其getDocumentAsync方法来检查是否已存在缓存中的相同操作。
public interface PreparsedDocumentProvider {CompletableFuture<PreparsedDocumentEntry> getDocumentAsync(ExecutionInput executionInput,Function<ExecutionInput, PreparsedDocumentEntry> parseAndValidateFunction);}
The getDocumentAsync方法接受两个参数:第一个是当前的“执行输入”,一个包含有关正在执行的查询的全部数据,包括操作字符串。
第二个是函数,parseAndValidateFunction,如果在缓存中没有找到提供的操作字符串时调用。此函数负责在将操作发送到数据获取方法之前执行必要的解析和验证步骤。但在过程中,操作本身会被缓存在下一次使用!
代码示例:CachingPreparsedDocumentProvider类
让我们来创建一个实现我们的PreparsedDocumentProvider接口的类。
在com.example.listings包中,与ListingsApplication文件并列,创建一个名为CachingPreparsedDocumentProvider.java的新文件。
📦 com.example.listings┣ 📂 datafetchers┣ 📂 dataloaders┣ 📂 datasources┣ 📂 models┣ 📄 CachingPreparsedDocumentProvider┣ 📄 ListingsApplication┗ 📄 WebConfiguration
首先,我们可以导入Spring框架的Component注解,以及来自graphql包的PreparsedDocumentProvider和PreparsedDocumentEntry。(我们很快就会用到!)
import org.springframework.stereotype.Component;import graphql.execution.preparsed.PreparsedDocumentProvider;import graphql.execution.preparsed.PreparsedDocumentEntry;
接下来,我们更新我们的类定义以实现实现的PreparsedDocumentProvider接口。别忘了应用@Component注解,这样文件就被检测为我们的应用程序中的一个bean(由Spring容器管理的类实例)。
以下是您类的样子。
package com.example.listings;import org.springframework.stereotype.Component;import graphql.execution.preparsed.PreparsedDocumentProvider;import graphql.execution.preparsed.PreparsedDocumentEntry;@Componentpublic class CachingPreparsedDocumentProvider implements PreparsedDocumentProvider {// TODO}
很好!我们已经处理好了这些样板。现在您可能看到一些红色的波浪线,但不用担心:我们将在下一课中构建我们类其余的部分。
缓存提示:使用查询变量
我们认为在GraphQL中GraphQL中使用查询变量是一种最佳实践,但GraphQL操作缓存时,这一惯例显得尤为重要。
请看一下以下查询。
query GetListingAndAmenities {listing(id: "listing-1") {titledescriptionnumOfBedsamenities {namecategory}overallRatingreviews {idtext}}}
这个查询语法没有问题——但是存储在我们的缓存中的这个操作仅对一个列表有效:ID为listing-1的列表!
如果我们再次运行同样的操作,用不同的列表ID替换,我们就不会看到缓存第一次操作的好处。操作中定义的列表ID是直接嵌入的,我们的缓存操作过于具体:它仅在我们查询与前一个列表完全相同的情况下节省时间。
query GetListingAndAmenities {listing(id: "listing-2") {titledescriptionnumOfBedsamenities {namecategory}overallRatingreviews {idtext}}}
有了查询变量,我们就可以抽象出具体信息,专注于通用操作:字段它包括以及涉及的变量名称。
query GetListingAndAmenities($listingId: ID!) {listing(id: $listingId) {titledescriptionnumOfBedsamenities {namecategory}overallRatingreviews {idtext}}}
现在,如果我们的客户端发送这个操作两次,一次用于listing-1,另一次用于listing-2,我们会看到操作缓存的优点:服务器第二次收到请求时,将跳过解析和验证步骤。
注意:关于实际在运行时传递的变量值?它们可以在传递到接口的getDocumentAsync方法的执行输入对象中找到。我们将在下一课中探索此对象。
练习
重要结论
- 我们可以实现
PreparsedDocumentProvider接口来进行以下操作:- 从中检索操作,这些操作已经从缓存中解析并验证过。
- 解析和验证操作,这些操作尚未缓存,在处理过程中进行缓存。
- 通过使用查询变量(而不是行内值),我们可以在缓存中存储通用操作,这些操作可以根据不同的值检索和使用。(例如,一个操作可以为任何我们提供的列表ID提供数据!)
接下来
在下一节课中,我们将通过添加方法和一个高性能缓存实现来完成我们的类实现。
分享您对这节课的疑问和评论
该课程目前处于
您需要在下面发表评论之前拥有GitHub账号。还没有吗? 请在我们的Odyssey论坛上发表。